





There is an Italian version of this article; if you'd like to read it click here.
Seamless technological upgrades of legacy infrastructures
A frontline web server exposing a backend application - who hasn't seen one?
This apparently simple logical architecture is obviously based on multiple instances that can guarantee high reliability and load balancing.
It is a model that has existed for decades, but the technologies to make it evolve. Sometimes, due to time or budget, or organizational reasons, it is not possible to modernize specific applications, for example, because they often belong to different teams with different priorities, or because the project group has been dissolved and the application must be "kept alive" as it is.
These situations are super common, and the result is that many old configurations are never deleted from web servers but instead continue to stratify more and more, even becoming extremely complex.
This complexity increases the risk of making a mistake when inserting a change exponentially, and the blast radius is potentially enormous in this situation.
To summarize, the use case I want to describe has the constraint of not intervening in the configurations and maintaining the logical architecture, but we want to act at a technological level to improve safety and reliability and minimize operational risk.
The solution I created is based on ECS Fargate, where I transformed old virtual machines into containers, and uses the same methodology that usually applies to backend applications, that is the blue/green deployment technique, with the execution of tests to decide whether a new configuration can go online safely.
Blue/green deployment
Blue/green deployment is an application release model that swaps traffic from an older version of an app or microservice to a new release. The previous version is called the blue environment, while the new version is called the green environment.
In this model, it is essential to test the green environment to ensure its readiness to handle production traffic. Once the tests are passed, this new version is promoted to production by reconfiguring the load balancer to transfer the incoming traffic from the blue environment to the green environment, running the latest version of the application at last.
Using this strategy increases application availability and reduces operational risk, while also the rollback process is simplified.
Fully managed updates with ECS Fargate
AWS CodePipeline supports fully automated blue/green releases on Amazon Elastic Container Service (ECS).
Normally, when you create an ECS service with an Application Load Balancer in front of it, you need to designate a target group that contains the microservices to receive the requests. The blue/green approach involves the creation of two target groups: one for the blue version and one for the green version of the service. It also uses a different listening port for each target group, so that you can test the green version of the service using the same path as the blue version.
With this configuration, you run both environments in parallel until you are ready to switch to the green version of the service.
When you are ready to replace the old blue version with the new green version, you swap the listener rules with the target group rules. This change takes place in seconds. At this point the green service is running in the target group with the listener of the "original" port (which previously belonged to the blue version) and the blue service is running in the target group with the listener of the port that was of the green version (until termination).
At this point, the real question is: how can this system decide if and when the green version is ready to replace the blue version?
You need a control logic that executes tests to evaluate whether the new version can replace the old one with a high degree of confidence. Swapping from the old to the new version is only allowed after passing these tests.
All these steps are fully automatic on ECS thanks to the complete integration of AWS CodePipeline + CodeBuild + CodeDeploy services. The control tests in my case are performed by a Lambda.
The following diagram illustrates the approach described.
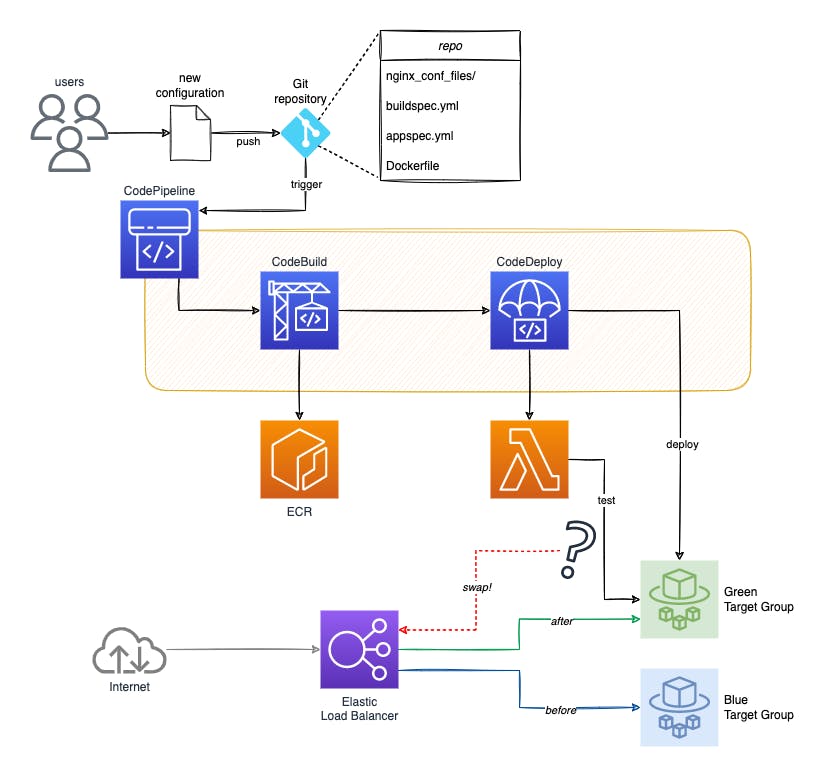
Using Terraform to build a blue/green deployment system on ECS
Creating an ECS cluster and a pipeline that builds the new version of the container image to deploy in blue/green mode is not difficult in itself but requires creating many cloud resources to coordinate. Below we will look at some of the key details in creating these assets with Terraform.
You can find the complete example at this link. Here are just some code snippets useful for examining the use case.
Application Load Balancer
One of the basic resources for our architecture is the load balancer. I enable access logs stored in a bucket because they will be used indirectly for the testing Lambda:
resource "aws_alb" "load_balancer" {
name = replace(local.name, "_", "-")
internal = false
access_logs {
bucket = aws_s3_bucket.logs_bucket.bucket
prefix = "alb_access_logs"
enabled = true
}
...
}
So I create two target groups, identical to each other:
resource "aws_alb_target_group" "tg_blue" {
name = join("-", [replace(local.name, "_", "-"), "blue"])
port = 80
protocol = "HTTP"
target_type = "ip"
...
}
resource "aws_alb_target_group" "tg_green" {
name = join("-", [replace(local.name, "_", "-"), "green"])
port = 80
protocol = "HTTP"
target_type = "ip"
...
}
As mentioned before, I create two listeners on two different ports, 80 and 8080 in this example. The meta-argument ignore_changes makes Terraform ignore future changes to the default_action that will have been performed by the blue/green deployment.
resource "aws_alb_listener" "lb_listener_80" {
load_balancer_arn = aws_alb.load_balancer.id
port = "80"
protocol = "HTTP"
default_action {
target_group_arn = aws_alb_target_group.tg_blue.id
type = "forward"
}
lifecycle {
ignore_changes = [default_action]
}
}
resource "aws_alb_listener" "lb_listener_8080" {
load_balancer_arn = aws_alb.load_balancer.id
port = "8080"
protocol = "HTTP"
default_action {
target_group_arn = aws_alb_target_group.tg_green.id
type = "forward"
}
lifecycle {
ignore_changes = [default_action]
}
}
ECS
In the configuration of the ECS cluster, the service definition includes the indication of the target group to be associated with the creation. This indication will be ignored in any subsequent Terraform runs:
resource "aws_ecs_service" "ecs_service" {
name = local.name
cluster = aws_ecs_cluster.ecs_cluster.id
task_definition = aws_ecs_task_definition.task_definition.arn
desired_count = 2
launch_type = "FARGATE"
deployment_controller {
type = "CODE_DEPLOY"
}
load_balancer {
target_group_arn = aws_alb_target_group.tg_blue.arn
container_name = local.name
container_port = 80
}
lifecycle {
ignore_changes = [task_definition, load_balancer, desired_count]
}
...
}
CodeCommit
The application code - in my case, the webserver configurations and the Dockerfile to create the image - is saved in a Git repository on CodeCommit. A rule is associated with this repository that intercepts every push event and triggers the pipeline:
resource "aws_codecommit_repository" "repo" {
repository_name = local.name
description = "${local.name} Repository"
}
resource "aws_cloudwatch_event_rule" "commit" {
name = "${local.name}-capture-commit-event"
description = "Capture ${local.name} repo commit"
event_pattern = <<EOF
{
"source": [
"aws.codecommit"
],
"detail-type": [
"CodeCommit Repository State Change"
],
"resources": [
"${aws_codecommit_repository.repo.arn}"
],
"detail": {
"referenceType": [
"branch"
],
"referenceName": [
"${aws_codecommit_repository.repo.default_branch}"
]
}
}
EOF
}
resource "aws_cloudwatch_event_target" "event_target" {
target_id = "1"
rule = aws_cloudwatch_event_rule.commit.name
arn = aws_codepipeline.codepipeline.arn
role_arn = aws_iam_role.codepipeline_role.arn
}
The Dockerfile that will be saved on this repository depends of course on the application. In my case I have a code structure like this:
.
├── version.txt
├── Dockerfile
└── etc
└── nginx
├── nginx.conf
└── conf.d
├── file1.conf
└── ...
└── projects.d
├── file2.conf
└── ...
└── upstream.d
└── file3.conf
└── ...
My Dockerfile will be therefore very simple:
FROM nginx:latest
COPY etc/nginx/nginx.conf /etc/nginx/nginx.conf
COPY etc/nginx/conf.d /etc/nginx/conf.d
COPY etc/nginx/projects.d /etc/nginx/projects.d/
COPY etc/nginx/upstream.d /etc/nginx/upstream.d/
COPY version.txt /usr/share/nginx/html/version.txt
CodeBuild
I then configure the step needed to generate the new version of the container through CodeBuild. The privileged_mode = true property enables the Docker daemon within the CodeBuild container.
resource "aws_codebuild_project" "codebuild" {
name = local.name
description = "${local.name} Codebuild Project"
build_timeout = "5"
service_role = aws_iam_role.codebuild_role.arn
artifacts {
type = "CODEPIPELINE"
}
environment {
compute_type = "BUILD_GENERAL1_SMALL"
image = "aws/codebuild/standard:6.0"
type = "LINUX_CONTAINER"
image_pull_credentials_type = "CODEBUILD"
privileged_mode = true
environment_variable {
name = "IMAGE_REPO_NAME"
value = aws_ecr_repository.ecr_repo.name
}
environment_variable {
name = "AWS_ACCOUNT_ID"
value = data.aws_caller_identity.current.account_id
}
}
source {
type = "CODEPIPELINE"
buildspec = "buildspec.yml"
}
}
The buildspec.yml file in the CodeBuild configuration is used to define how to generate the container image. This file is included in the repository along with the code, and it looks like this:
version: 0.2
env:
shell: bash
phases:
install:
runtime-versions:
docker: 19
pre_build:
commands:
- IMAGE_TAG=$CODEBUILD_BUILD_NUMBER
- echo Logging in to Amazon ECR...
- $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION)
build:
commands:
- echo Build started on `date`
- echo Building the Docker image...
- docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG .
- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG
- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest
post_build:
commands:
- echo Build completed on `date`
- echo Pushing to repo
- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest
- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG
CodeDeploy
The CodeDeploy configuration includes three different resources. The first two are relatively simple:
resource "aws_codedeploy_app" "codedeploy_app" {
compute_platform = "ECS"
name = local.name
}
resource "aws_codedeploy_deployment_config" "config_deploy" {
deployment_config_name = local.name
compute_platform = "ECS"
traffic_routing_config {
type = "AllAtOnce"
}
}
I finally configure the blue/green deployment. With this code I indicate:
to perform an automatic rollback in case of deployment failure
if successful, terminate the old version after 5 minutes
listeners for "normal" (prod) traffic and test traffic
resource "aws_codedeploy_deployment_group" "codedeploy_deployment_group" {
app_name = aws_codedeploy_app.codedeploy_app.name
deployment_group_name = local.name
service_role_arn = aws_iam_role.codedeploy_role.arn
deployment_config_name = aws_codedeploy_deployment_config.config_deploy.deployment_config_name
ecs_service {
cluster_name = aws_ecs_cluster.ecs_cluster.name
service_name = aws_ecs_service.ecs_service.name
}
auto_rollback_configuration {
enabled = true
events = ["DEPLOYMENT_FAILURE"]
}
deployment_style {
deployment_option = "WITH_TRAFFIC_CONTROL"
deployment_type = "BLUE_GREEN"
}
blue_green_deployment_config {
deployment_ready_option {
action_on_timeout = "CONTINUE_DEPLOYMENT"
wait_time_in_minutes = 0
}
terminate_blue_instances_on_deployment_success {
action = "TERMINATE"
termination_wait_time_in_minutes = 5
}
}
load_balancer_info {
target_group_pair_info {
target_group {
name = aws_alb_target_group.tg_blue.name
}
target_group {
name = aws_alb_target_group.tg_green.name
}
prod_traffic_route {
listener_arns = [aws_alb_listener.lb_listener_80.arn]
}
test_traffic_route {
listener_arns = [aws_alb_listener.lb_listener_8080.arn]
}
}
}
}
It is necessary to insert in the Git repository, together with the code, also two files essential for the correct functioning of CodeDeploy.
The first file is taskdef.json and includes the task definition for our ECS service, with the indication of container image, executionRole and logConfiguration to be inserted according to the resources created by Terraform. For example:
{
"executionRoleArn": "arn:aws:iam::123456789012:role/ECS_role_BlueGreenDemo",
"containerDefinitions": [
{
"name": "BlueGreenDemo",
"image": "123456789012.dkr.ecr.eu-west-1.amazonaws.com/BlueGreenDemo_repository:latest",
"essential": true,
"portMappings": [
{
"hostPort": 80,
"protocol": "tcp",
"containerPort": 80
}
],
"ulimits": [
{
"name": "nofile",
"softLimit": 4096,
"hardLimit": 4096
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/aws/ecs/BlueGreenDemo",
"awslogs-region": "eu-south-1",
"awslogs-stream-prefix": "nginx"
}
}
}
],
"requiresCompatibilities": [
"FARGATE"
],
"networkMode": "awsvpc",
"cpu": "256",
"memory": "512",
"family": "BlueGreenDemo"
}
The second file to include in the repository is appspec.yml, which is the file used by CodeDeploy to perform release operations. The task definition is set with a placeholder (because the real file path will be referenced in the CodePipeline configuration), and the name of the lambda to run for the tests is indicated.
In our case, the lambda must be executed when the AfterAllowTestTraffic event arrives, that is, when the new version is ready to receive the test traffic. Other possible hooks are documented on this page; my choice depended on my use case and how I decided to implement my tests.
version: 0.0
Resources:
- TargetService:
Type: AWS::ECS::Service
Properties:
TaskDefinition: "<TASK_DEFINITION>"
LoadBalancerInfo:
ContainerName: "BlueGreenDemo"
ContainerPort: 80
Hooks:
- AfterAllowTestTraffic: "BlueGreenDemo_lambda"
Lambda
The Lambda function that performs the tests is created by Terraform, and some environment variables are also configured, the purpose of which will be explained later:
resource "aws_lambda_function" "lambda" {
function_name = "${local.name}_lambda"
role = aws_iam_role.lambda_role.arn
handler = "app.lambda_handler"
runtime = "python3.8"
timeout = 300
s3_bucket = aws_s3_bucket.lambda_bucket.bucket
s3_key = aws_s3_object.lambda_object.key
environment {
variables = {
BUCKET = aws_s3_bucket.testdata_bucket.bucket
FILEPATH = "acceptance_url_list.csv"
ENDPOINT = "${local.custom_endpoint}:8080"
ACCEPTANCE_THRESHOLD = "90"
}
}
}
resource "aws_s3_object" "lambda_object" {
key = "${local.name}/dist.zip"
bucket = aws_s3_bucket.lambda_bucket.bucket
source = data.archive_file.lambda_zip_file.output_path
}
data "archive_file" "lambda_zip_file" {
type = "zip"
output_path = "${path.module}/${local.name}-lambda.zip"
source_file = "${path.module}/../lambda/app.py"
}
CodePipeline
Finally, to make all the resources seen so far interact correctly, I configure CodePipeline to orchestrate the three stages corresponding to:
download the source code from CodeCommit
build of the container image performed by CodeBuild
a release made by CodeDeploy
resource "aws_codepipeline" "codepipeline" {
name = local.name
role_arn = aws_iam_role.codepipeline_role.arn
artifact_store {
location = aws_s3_bucket.codepipeline_bucket.bucket
type = "S3"
}
stage {
name = "Source"
action {
name = "Source"
category = "Source"
owner = "AWS"
provider = "CodeCommit"
version = "1"
output_artifacts = ["source_output"]
configuration = {
RepositoryName = aws_codecommit_repository.repo.repository_name
BranchName = aws_codecommit_repository.repo.default_branch
PollForSourceChanges = false
}
}
}
stage {
name = "Build"
action {
name = "Build"
category = "Build"
owner = "AWS"
provider = "CodeBuild"
input_artifacts = ["source_output"]
output_artifacts = ["build_output"]
version = "1"
configuration = {
ProjectName = aws_codebuild_project.codebuild.name
}
}
}
stage {
name = "Deploy"
action {
category = "Deploy"
name = "Deploy"
owner = "AWS"
provider = "CodeDeployToECS"
version = "1"
input_artifacts = ["source_output"]
configuration = {
ApplicationName = local.name
DeploymentGroupName = local.name
AppSpecTemplateArtifact = "source_output"
AppSpecTemplatePath = "appspec.yaml"
TaskDefinitionTemplateArtifact = "source_output"
TaskDefinitionTemplatePath = "taskdef.json"
}
}
}
}
Purpose of the tests and implementation logic of Lambda
The purpose of the control test on the new version of the service to be deployed is not to verify that the new configurations are working and conform to expectations, but rather that they do not introduce "regressions" on the previous behaviour of the web server. In essence, this is a mechanism to reduce the risk of "breaking" something that used to work - which is extremely important in the case of an infrastructure shared by many applications.
The idea behind this Lambda is to make a series of requests to the new version of the service when it has been created and is ready to receive traffic, but the load balancer is still configured with the old version (trigger event of the AfterAllowTestTraffic hook configured in the CodeDeploy appspec.yml).
The list of URLs to be tested must be prepared with a separate process: it may be a static list, but in my case, having no control or visibility on the URLs delivered dynamically from the backend (think about a CMS: tons of URLs that can change anytime), I created a night job whose starting point is the webserver access logs of the day before; but I also had to take into account URLs that are rarely visited and that may not be present in the access logs every day. Furthermore, the execution time of a Lambda is limited, therefore a significant subset of URLs must be carefully chosen in order not to prolong the execution excessively and risk the timeout.
The process of creating this list is linked to how many and which URLs are served by the web server. Therefore it is not possible to provide suggestions on a unique way to generate the list: it is strictly dependent on the use case. The list of URLs of requests to be made is contained, in my example, in the file acceptance_url_list.csv on an S3 bucket.
The environment variables used by my Lambda include the bucket and path of this file, the endpoint to send requests to and a parameter introduced to allow for a margin of error. The applications to which the web server sends requests may change as a result of application releases and the URLs that were functional the day before may no longer be reachable; not being able to have complete control, especially in very complex infrastructures, I have chosen to introduce a threshold corresponding to the percentage of requests that must obtain an HTTP 200 response for the test to be considered passed.
Once the logic described is understood, the Lambda code is not particularly complex: the function makes the requests listed in the list, calculates the percentage of successes, and finally notifies CodeDeploy of the outcome of the test.
import boto3
import urllib.request
import os
import csv
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event,context):
codedeploy = boto3.client('codedeploy')
endpoint = os.environ['ENDPOINT']
bucket = os.environ['BUCKET']
file = os.environ['FILEPATH']
source_file = "s3://"+os.environ['BUCKET']+"/"+os.environ['FILEPATH']
perc_min = os.environ['ACCEPTANCE_THRESHOLD']
count_200 = 0
count_err = 0
s3client = boto3.client('s3')
try:
s3client.download_file(bucket, file, "/tmp/"+file)
except:
pass
with open("/tmp/"+file, newline='') as f:
reader = csv.reader(f)
list1 = list(reader)
for url_part in list1:
code = 0
url = "http://"+endpoint+url_part[0]
try:
request = urllib.request.urlopen(url)
code = request.code
if code == 200:
count_200 = count_200 + 1
else:
count_err = count_err + 1
except:
count_err = count_err + 1
if code == 0:
logger.info(url+" Error")
else:
logger.info(url+" "+str(code))
status = 'Failed'
perc_200=(int((count_200/(count_200+count_err))*100))
logger.info("HTTP 200 response percentage: ")
logger.info(perc_200)
if perc_200 > int(perc_min):
status = "Succeeded"
logger.info("TEST RESULT: ")
logger.info(status)
codedeploy.put_lifecycle_event_hook_execution_status(
deploymentId=event["DeploymentId"],
lifecycleEventHookExecutionId=event["LifecycleEventHookExecutionId"],
status=status
)
return True
Integration is a "tailoring" activity
In this article, we have seen how to integrate and coordinate many different objects to make them converge towards end-to-end automation, also including resources that need to be tailored to the specific use case.
Automation of releases is an activity that I find very rewarding. Historically, releases have always been a thorn in the side, precisely because the activity was manual, not subject to any tests, with many unexpected variables: fortunately, as we have seen, it is now possible to rely on a well-defined, clear and repeatable process.
The tools we have available for automation are very interesting and versatile, but the cloud doesn't do it all by itself. However, some important integration work is necessary (the code we have seen is only a part; the complete example is here), and above all knowing how to adapt the resources to the use case, always looking for the best solution to solve the specific problem.