





If you're looking for the English version of this article, click here.
Upgrade tecnologici seamless di infrastrutture legacy
Un webserver in prima linea che espone un'applicazione di backend: chi non ne ha visto uno?
Questa appartentemente semplice architettura logica ovviamente si realizza su istanze multiple che possano garantire alta affidabilità e bilanciamento di carico.
E' un modello che esiste da decenni, ma le tecnologie per realizzarlo si evolvono. A volte, per motivi di tempo o di budget, oppure organizzativi, non è possibile modernizzare certe applicazioni, ad esempio perché spesso fanno capo a team diversi con priorità differenti, oppure perché il gruppo di progetto è stato sciolto e l'applicazione va "tenuta in vita" così com'è.
Queste situazioni sono molto comuni e il risultato è che tantissime vecchie configurazioni non vengono mai dismesse dai webserver ma continuano invece a stratificarsi sempre di più, fino a diventare anche estremamente complesse.
Questa complessità fa aumentare esponenzialmente il rischio di fare un errore in fase di inserimento di una modifica, e in questo caso il blast radius è potenzialmente enorme.
Per riassumere, il caso d'uso che voglio descrivere ha il vincolo di non poter intervenire sulle configurazioni e quindi di mantenere l'architettura logica, ma si vuole agire a livello tecnologico per migliorare la sicurezza e l'affidabilità e minimizzare il rischio operativo.
La soluzione che ho realizzato è basata su ECS Fargate, dove ho trasformato delle vecchie virtual machine in container, e utilizza la stessa metodologia che di solito viene utilizzata per le applicazioni di backend, ovvero la tecnica di deployment blue/green con l’esecuzione di test che decidono se una nuova configurazione può andare online in modo sicuro.
Blue/green deployment
Il deployment blue/green è un modello di rilascio delle applicazioni che prevede lo swap del traffico da una versione precedente di un'app o microservizio a una nuova release. La versione precedente viene chiamata ambiente blue, mentre la nuova versione prende il nome di ambiente green.
In questo modello, è fondamentale eseguire dei test sull'ambiente green per garantire che sia pronto a gestire il traffico di produzione. Una volta superati i test, la nuova versione viene promossa in produzione riconfigurando il load balancer per trasferire il traffico in ingresso dall'ambiente blue all'ambiente green, eseguendo finalmente l'ultima versione dell'applicazione.
L'utilizzo di questa strategia aumenta la disponibilità delle applicazioni e riduce il rischio operativo, semplificando inoltre il processo di rollback se un aggiornamento non riesce.
Aggiornamenti completamente gestiti con ECS Fargate
AWS CodePipeline supporta rilasci su Amazon Elastic Container Service (ECS) con strategia blue/green in modalità completamente automatizzata.
Normalmente quando si crea un servizio ECS con davanti un Application Load Balancer, bisogna designare un target group che contenga i microservizi destinatari delle richieste. L'approccio blue/green prevede la creazione di due target group: uno per la versione blue e uno per la versione green del servizio. Si utilizza anche una porta in ascolto diversa per ciascun target group, in modo che si possa testare la versione green del servizio utilizzando lo stesso percorso della versione blu.
Con questa configurazione, in pratica si eseguono entrambi gli ambienti in parallelo finché non si è pronti per passare alla versione green del servizio.
Quando si è pronti per sostituire la vecchia versione blue con la nuova versione green, si scambiano le regole del listener con le regole del target group. La modifica avviene in pochi secondi. A questo punto il servizio green è in esecuzione nel target group con il listener della porta "originale" (che prima apparteneva alla versione blue) e il servizio blue è in esecuzione nel target group con il listener della porta che era stata della versione green (fin quando non viene terminato).
A questo punto la vera domanda è: come fa questo sistema a decidere se e quando la versione green è pronta a sostituire la versione blue?
E' necessario introdurre una logica di controllo che si occupi di effettuare i test necessari a valutare se la nuova versione può sostituire la vecchia con un grado di confidenza elevato. Lo swap dalla vecchia alla nuova versione è consentito solo dopo il superamento di questi test.
Tutti i passaggi descritti avvengono su ECS in modalità completamente automatica grazie alla completa integrazione dei servizi AWS CodePipeline + CodeBuild + CodeDeploy. I test di controllo nel mio caso sono eseguiti da una Lambda.
Il diagramma seguente illustra l'approccio descritto.
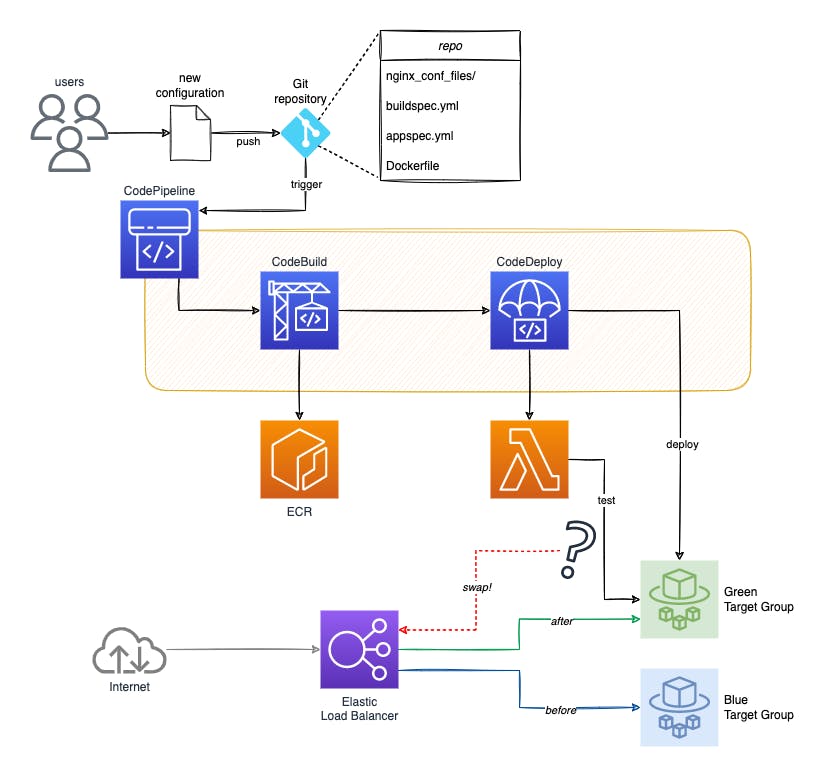
ECS e blue/green deployment con Terraform
Creare un cluster ECS e una pipeline che buildi la nuova versione della container image da deployare in modalità blue/green non è di per sé difficile, ma richiede la creazione di molte risorse cloud da coordinare. Di seguito vedremo alcuni dei dettagli fondamentali nel creare queste risorse con Terraform.
Puoi trovare l'esempio completo a questo link. Di seguito riportiamo solo alcuni frammenti di codice utili alla disamina del caso d'uso.
Application Load Balancer
Una delle risorse basilari per la nostra architettura è il load balancer. Abilito il salvataggio degli access log in un bucket, perché serviranno indirettamente per la Lambda di test:
resource "aws_alb" "load_balancer" {
name = replace(local.name, "_", "-")
internal = false
access_logs {
bucket = aws_s3_bucket.logs_bucket.bucket
prefix = "alb_access_logs"
enabled = true
}
...
}
Creo quindi due target group, identici tra loro:
resource "aws_alb_target_group" "tg_blue" {
name = join("-", [replace(local.name, "_", "-"), "blue"])
port = 80
protocol = "HTTP"
target_type = "ip"
...
}
resource "aws_alb_target_group" "tg_green" {
name = join("-", [replace(local.name, "_", "-"), "green"])
port = 80
protocol = "HTTP"
target_type = "ip"
...
}
Come accennato prima, creo due listener su due porte diverse, nell'esempio 80 e 8080. Il meta-argument ignore_changes serve a far sì che Terraform ignori modifiche future alla default_action che saranno state eseguite dal blue/green deployment.
resource "aws_alb_listener" "lb_listener_80" {
load_balancer_arn = aws_alb.load_balancer.id
port = "80"
protocol = "HTTP"
default_action {
target_group_arn = aws_alb_target_group.tg_blue.id
type = "forward"
}
lifecycle {
ignore_changes = [default_action]
}
}
resource "aws_alb_listener" "lb_listener_8080" {
load_balancer_arn = aws_alb.load_balancer.id
port = "8080"
protocol = "HTTP"
default_action {
target_group_arn = aws_alb_target_group.tg_green.id
type = "forward"
}
lifecycle {
ignore_changes = [default_action]
}
}
ECS
Nella configurazione del cluster ECS la definizione del service include l'indicazione del target group da associare alla creazione, indicazione che verrà ignorata in eventuali esecuzioni successive di Terraform:
resource "aws_ecs_service" "ecs_service" {
name = local.name
cluster = aws_ecs_cluster.ecs_cluster.id
task_definition = aws_ecs_task_definition.task_definition.arn
desired_count = 2
launch_type = "FARGATE"
deployment_controller {
type = "CODE_DEPLOY"
}
load_balancer {
target_group_arn = aws_alb_target_group.tg_blue.arn
container_name = local.name
container_port = 80
}
lifecycle {
ignore_changes = [task_definition, load_balancer, desired_count]
}
...
}
CodeCommit
Il codice dell'applicazione - nel mio caso, le configurazioni del webserver e il Dockerfile per creare l'immagine - è salvato in un repository Git su CodeCommit. A questo repository è associata una regola che intercetta ogni evento di push e triggera la pipeline:
resource "aws_codecommit_repository" "repo" {
repository_name = local.name
description = "${local.name} Repository"
}
resource "aws_cloudwatch_event_rule" "commit" {
name = "${local.name}-capture-commit-event"
description = "Capture ${local.name} repo commit"
event_pattern = <<EOF
{
"source": [
"aws.codecommit"
],
"detail-type": [
"CodeCommit Repository State Change"
],
"resources": [
"${aws_codecommit_repository.repo.arn}"
],
"detail": {
"referenceType": [
"branch"
],
"referenceName": [
"${aws_codecommit_repository.repo.default_branch}"
]
}
}
EOF
}
resource "aws_cloudwatch_event_target" "event_target" {
target_id = "1"
rule = aws_cloudwatch_event_rule.commit.name
arn = aws_codepipeline.codepipeline.arn
role_arn = aws_iam_role.codepipeline_role.arn
}
Il Dockerfile che andrà salvato su questo repository dipende naturalmente dall'applicazione. Nel mio caso ho una struttura di codice fatta così:
.
├── version.txt
├── Dockerfile
└── etc
└── nginx
├── nginx.conf
└── conf.d
├── file1.conf
└── ...
└── projects.d
├── file2.conf
└── ...
└── upstream.d
└── file3.conf
└── ...
il Dockerfile, quindi, sarà molto semplice:
FROM nginx:latest
COPY etc/nginx/nginx.conf /etc/nginx/nginx.conf
COPY etc/nginx/conf.d /etc/nginx/conf.d
COPY etc/nginx/projects.d /etc/nginx/projects.d/
COPY etc/nginx/upstream.d /etc/nginx/upstream.d/
COPY version.txt /usr/share/nginx/html/version.txt
CodeBuild
Configuro quindi lo step che serve a generare la nuova versione del container tramite CodeBuild. La proprietà privileged_mode = true abilita il daemon Docker all'interno del container di CodeBuild.
resource "aws_codebuild_project" "codebuild" {
name = local.name
description = "${local.name} Codebuild Project"
build_timeout = "5"
service_role = aws_iam_role.codebuild_role.arn
artifacts {
type = "CODEPIPELINE"
}
environment {
compute_type = "BUILD_GENERAL1_SMALL"
image = "aws/codebuild/standard:6.0"
type = "LINUX_CONTAINER"
image_pull_credentials_type = "CODEBUILD"
privileged_mode = true
environment_variable {
name = "IMAGE_REPO_NAME"
value = aws_ecr_repository.ecr_repo.name
}
environment_variable {
name = "AWS_ACCOUNT_ID"
value = data.aws_caller_identity.current.account_id
}
}
source {
type = "CODEPIPELINE"
buildspec = "buildspec.yml"
}
}
Nella configurazione di CodeBuild è indicato il file buildspec.yml che serve a definire come generare la container image. Questo file sarà contenuto nel repository assieme al codice, e avrà una forma di questo tipo:
version: 0.2
env:
shell: bash
phases:
install:
runtime-versions:
docker: 19
pre_build:
commands:
- IMAGE_TAG=$CODEBUILD_BUILD_NUMBER
- echo Logging in to Amazon ECR....
- $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION)
build:
commands:
- echo Build started on `date`
- echo Building the Docker image...
- docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG .
- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG
- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest
post_build:
commands:
- echo Build completed on `date`
- echo Pushing to repo
- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:latest
- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG
CodeDeploy
La configurazione di CodeDeploy comprende tre diverse risorse. Le prime due sono relativamente semplici:
resource "aws_codedeploy_app" "codedeploy_app" {
compute_platform = "ECS"
name = local.name
}
resource "aws_codedeploy_deployment_config" "config_deploy" {
deployment_config_name = local.name
compute_platform = "ECS"
traffic_routing_config {
type = "AllAtOnce"
}
}
Configuro finalmente il blue/green deployment. Con questo codice indico:
di effettuare un rollback automatico in caso di fallimento del deployment
in caso di successo, di terminare la vecchia versione dopo 5 minuti
i listener del traffico "normale" (prod) e del traffico di test
resource "aws_codedeploy_deployment_group" "codedeploy_deployment_group" {
app_name = aws_codedeploy_app.codedeploy_app.name
deployment_group_name = local.name
service_role_arn = aws_iam_role.codedeploy_role.arn
deployment_config_name = aws_codedeploy_deployment_config.config_deploy.deployment_config_name
ecs_service {
cluster_name = aws_ecs_cluster.ecs_cluster.name
service_name = aws_ecs_service.ecs_service.name
}
auto_rollback_configuration {
enabled = true
events = ["DEPLOYMENT_FAILURE"]
}
deployment_style {
deployment_option = "WITH_TRAFFIC_CONTROL"
deployment_type = "BLUE_GREEN"
}
blue_green_deployment_config {
deployment_ready_option {
action_on_timeout = "CONTINUE_DEPLOYMENT"
wait_time_in_minutes = 0
}
terminate_blue_instances_on_deployment_success {
action = "TERMINATE"
termination_wait_time_in_minutes = 5
}
}
load_balancer_info {
target_group_pair_info {
target_group {
name = aws_alb_target_group.tg_blue.name
}
target_group {
name = aws_alb_target_group.tg_green.name
}
prod_traffic_route {
listener_arns = [aws_alb_listener.lb_listener_80.arn]
}
test_traffic_route {
listener_arns = [aws_alb_listener.lb_listener_8080.arn]
}
}
}
}
E' necessario inserire nel repository Git, assieme al codice, anche due file indispensabili al corretto funzionamento di CodeDeploy.
Il primo file è taskdef.json e include la task definition per il nostro servizio ECS, con l'indicazione di container image, executionRole e logConfiguration da inserire secondo le risorse creare da Terraform. Ad esempio:
{
"executionRoleArn": "arn:aws:iam::123456789012:role/ECS_role_BlueGreenDemo",
"containerDefinitions": [
{
"name": "BlueGreenDemo",
"image": "123456789012.dkr.ecr.eu-west-1.amazonaws.com/BlueGreenDemo_repository:latest",
"essential": true,
"portMappings": [
{
"hostPort": 80,
"protocol": "tcp",
"containerPort": 80
}
],
"ulimits": [
{
"name": "nofile",
"softLimit": 4096,
"hardLimit": 4096
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/aws/ecs/BlueGreenDemo",
"awslogs-region": "eu-south-1",
"awslogs-stream-prefix": "nginx"
}
}
}
],
"requiresCompatibilities": [
"FARGATE"
],
"networkMode": "awsvpc",
"cpu": "256",
"memory": "512",
"family": "BlueGreenDemo"
}
Il secondo file da includere nel repository è appspec.yml, che è il file realmente usato da CodeDeploy per eseguire le operazioni di rilascio. La task definition è impostata con un placeholder (perché il filepath reale sarà referenziato nella configurazione di CodePipeline), ed è indicato il nome della lambda da eseguire per i test.
Nel nostro caso, la lambda deve essere eseguita all'arrivo dell'evento AfterAllowTestTraffic, ovvero quando la nuova versione è pronta a ricevere il traffico di test. Altri possibili hooks sono documentati in questa pagina; la mia scelta è dipesa dal mio caso d'uso e da come ho deciso di implementare i miei test.
version: 0.0
Resources:
- TargetService:
Type: AWS::ECS::Service
Properties:
TaskDefinition: "<TASK_DEFINITION>"
LoadBalancerInfo:
ContainerName: "BlueGreenDemo"
ContainerPort: 80
Hooks:
- AfterAllowTestTraffic: "BlueGreenDemo_lambda"
Lambda
La Lambda che effettua i test viene creata da Terraform, e sono configurate anche alcune variabili d'ambiente, il cui scopo verrà spiegato successivamente:
resource "aws_lambda_function" "lambda" {
function_name = "${local.name}_lambda"
role = aws_iam_role.lambda_role.arn
handler = "app.lambda_handler"
runtime = "python3.8"
timeout = 300
s3_bucket = aws_s3_bucket.lambda_bucket.bucket
s3_key = aws_s3_object.lambda_object.key
environment {
variables = {
BUCKET = aws_s3_bucket.testdata_bucket.bucket
FILEPATH = "acceptance_url_list.csv"
ENDPOINT = "${local.custom_endpoint}:8080"
ACCEPTANCE_THRESHOLD = "90"
}
}
}
resource "aws_s3_object" "lambda_object" {
key = "${local.name}/dist.zip"
bucket = aws_s3_bucket.lambda_bucket.bucket
source = data.archive_file.lambda_zip_file.output_path
}
data "archive_file" "lambda_zip_file" {
type = "zip"
output_path = "${path.module}/${local.name}-lambda.zip"
source_file = "${path.module}/../lambda/app.py"
}
CodePipeline
Per finire, affinché tutte le risorse viste finora possano interagire correttamente, configuro CodePipeline per orchestrare i tre stage corrispondente a:
download del codice sorgente da CodeCommit
build della container image eseguita da CodeBuild
rilascio effettuato da CodeDeploy
resource "aws_codepipeline" "codepipeline" {
name = local.name
role_arn = aws_iam_role.codepipeline_role.arn
artifact_store {
location = aws_s3_bucket.codepipeline_bucket.bucket
type = "S3"
}
stage {
name = "Source"
action {
name = "Source"
category = "Source"
owner = "AWS"
provider = "CodeCommit"
version = "1"
output_artifacts = ["source_output"]
configuration = {
RepositoryName = aws_codecommit_repository.repo.repository_name
BranchName = aws_codecommit_repository.repo.default_branch
PollForSourceChanges = false
}
}
}
stage {
name = "Build"
action {
name = "Build"
category = "Build"
owner = "AWS"
provider = "CodeBuild"
input_artifacts = ["source_output"]
output_artifacts = ["build_output"]
version = "1"
configuration = {
ProjectName = aws_codebuild_project.codebuild.name
}
}
}
stage {
name = "Deploy"
action {
category = "Deploy"
name = "Deploy"
owner = "AWS"
provider = "CodeDeployToECS"
version = "1"
input_artifacts = ["source_output"]
configuration = {
ApplicationName = local.name
DeploymentGroupName = local.name
AppSpecTemplateArtifact = "source_output"
AppSpecTemplatePath = "appspec.yaml"
TaskDefinitionTemplateArtifact = "source_output"
TaskDefinitionTemplatePath = "taskdef.json"
}
}
}
}
Scopo dei test e logica implementativa della Lambda
Lo scopo del test di controllo sulla nuova versione del servizio da deployare non è tanto di verificare che le nuove configurazioni siano funzionanti e conformi alle aspettative, quanto invece che non introducano "regressioni" sul comportamento precedente del webserver. In sostanza si tratta di un meccanismo per ridurre il rischio di "rompere" qualcosa che prima funzionava - che è estremamente importante nel caso di un'infrastruttura condivisa da numerose applicazioni.
L'idea alla base della Lambda è quindi di effettuare una serie di richieste alla nuova versione del servizio quando esso è stato creato ed è pronto a ricevere traffico, ma il load balancer è ancora configurato con la vecchia versione (evento scatenante dell'hook AfterAllowTestTraffic configurato nell'appspec.yml di CodeDeploy).
La lista delle URL da testare deve essere preparata con un processo separato: può benissimo essere una lista statica, ma nel mio caso, non avendo controllo né visibilità sulle URL erogate in modalità dinamica dal backend (si pensi a un CMS), ho creato un job notturno la cui base di partenza sono gli access log del webserver del giorno prima; ma ho dovuto anche tener conto di URL che sono visitate raramente e che possono non essere presenti negli access log ogni giorno. Inoltre il tempo di esecuzione di una Lambda è limitato, pertanto va scelto con cura un sottoinsieme significativo di URL per non prolungare eccessivamente l'esecuzione rischiando il timeout.
In sostanza, il processo di creazione di questa lista è legato a quante e quali URL vengono servite dal webserver. Pertanto non è possibile fornire suggerimenti su una modalità univoca per generare la lista: è strettamente dipendente dal caso d'uso. La lista delle URL delle richieste da effettuare sono contenute, nel mio esempio, nel file acceptance_url_list.csv su un bucket S3.
Le variabili d'ambiente che servono alla Lambda comprendono bucket e path di questo file, l'endpoint a cui inviare le richieste e un parametro introdotto per consentire un margine d'errore. Infatti le applicazioni verso cui il webserver invia le richieste possono cambiare a seguito di rilasci applicativi e le URL che erano funzionanti il giorno prima potrebbero non essere più raggiungibili; non potendo avere il controllo completo, soprattutto in infrastrutture molto complesse, ho scelto di introdurre una soglia corrispondente alla percentuale di richieste che devono ottenere una risposta HTTP 200 affinché il test sia considerato superato.
Una volta compresa la logica descritta, il codice della Lambda non è particolarmente complesso: la funzione effettua le richieste elencate nella lista, calcola la percentuale di successi, e infine notifica a CodeDeploy l'esito del test.
import boto3
import urllib.request
import os
import csv
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event,context):
codedeploy = boto3.client('codedeploy')
endpoint = os.environ['ENDPOINT']
bucket = os.environ['BUCKET']
file = os.environ['FILEPATH']
source_file = "s3://"+os.environ['BUCKET']+"/"+os.environ['FILEPATH']
perc_min = os.environ['ACCEPTANCE_THRESHOLD']
count_200 = 0
count_err = 0
s3client = boto3.client('s3')
try:
s3client.download_file(bucket, file, "/tmp/"+file)
except:
pass
with open("/tmp/"+file, newline='') as f:
reader = csv.reader(f)
list1 = list(reader)
for url_part in list1:
code = 0
url = "http://"+endpoint+url_part[0]
try:
request = urllib.request.urlopen(url)
code = request.code
if code == 200:
count_200 = count_200 + 1
else:
count_err = count_err + 1
except:
count_err = count_err + 1
if code == 0:
logger.info(url+" Error")
else:
logger.info(url+" "+str(code))
status = 'Failed'
perc_200=(int((count_200/(count_200+count_err))*100))
logger.info("HTTP 200 response percentage: ")
logger.info(perc_200)
if perc_200 > int(perc_min):
status = "Succeeded"
logger.info("TEST RESULT: ")
logger.info(status)
codedeploy.put_lifecycle_event_hook_execution_status(
deploymentId=event["DeploymentId"],
lifecycleEventHookExecutionId=event["LifecycleEventHookExecutionId"],
status=status
)
return True
L'integrazione è un'attività "sartoriale"
In questo articolo abbiamo visto come integrare e coordinare molti oggetti diversi per farli convergere verso un'automazione end-to-end, includendo anche risorse che hanno necessità di essere cucite su misura per lo specifico caso d'uso.
L'automazione dei rilasci è un'attività che personalmente trovo molto gratificante. Storicamente i rilasci sono sempre stati una spina nel fianco, proprio perché l'attività era manuale, non soggetta ad alcun test, con tante variabili impreviste: fortunatamente, come abbiamo visto, è oggi possibile affidarsi a un processo ben definito, chiaro e ripetibile.
Gli strumenti che abbiamo a disposizione per l'automazione sono molto interessanti e versatili; ma il cloud non fa tutto da solo. E' comunque necessario un lavoro di integrazione di una certa importanza (il codice che abbiamo visto è solo una parte; l'esempio completo si trova qui), e soprattutto saper adattare le risorse al caso d'uso, cercando sempre la soluzione migliore per risolvere il problema specifico.