

EKS Autoscaling: Cluster Autoscaler (versione italiana)
Come configurare il node autoscaling per EKS con Terraform: parte prima




Photo by Eric Prouzet on Unsplash
If you're looking for the English version of this article, click here.
Un caso d'uso particolare
Qualche tempo fa mi è capitato un caso d'uso interessante in cui un'applicazione doveva consentire agli utilizzatori di lanciare l'esecuzione di simulazioni basate su algoritmi e parametri selezionati da un database.
Le simulazioni fondamentalmente erano dei job batch su Kubernetes che richiedevano una quantità fissata di risorse in termini di CPU e memoria, in modo da poter essere comparabili: lo scopo finale era infatti quello di valutare quale fosse il miglior algoritmo tra quelli eseguiti nelle simulazioni.
Si desiderava rendere gli utenti felici di poter eseguire le loro elaborazioni in modo indipendente, senza dover attendere la fine di un'altra elaborazione per mancanza di risorse computazionali libere; ma l'obiettivo finale era di mantenere i costi più bassi possibile.
La soluzione è stata realizzata su AWS EKS con l'utilizzo di due managed node group: un node group più "stabile" per ospitare l'applicazione, e un altro node group più "volatile" per l'esecuzione delle simulazioni, dove i nodi hanno maggiori risorse di calcolo ma vengono istanziati solo su richiesta di nuove simulazioni. Questo scaling dei nodi è gestito da Cluster Autoscaler che si occupa anche di fare down-sizing del node group fino a 0.
Cluster Autoscaler
Cluster Autoscaler è un tool vendor-neutral, open-source, incluso nel progetto Kubernetes e, ad oggi, è lo standard de-facto per l'implementazione del cluster autoscaling, con implementazioni fornite dalla maggior parte dei cloud provider.
Integrazione con i cloud provider
A seconda del cloud provider, Cluster Autoscaler può essere integrato di default o meno. Ad esempio Google Cloud Platform lo fornisce per impostazione predefinita in GKE:
Questa integrazione così profonda col cloud provider non sorprende: Google ha praticamente inventato Kubernetes, rilasciando a metà 2014 la versione open-source del suo progetto Borg, che a sua volta era nato internamente all'azienda nel 2003-2004.
AWS ha storicamente rilasciato negli anni un servizio innovativo dopo l'altro, e anche nell'ambito degli orchestatori di container ha puntato sul suo prodotto proprietario, ECS, che ha l'innegabile pregio di offrire all'utente la possibilità di utilizzarlo anche senza avere l'esperienza necessaria a gestire Kubernetes, ed è, naturalmente, integrato con tutti i servizi AWS.
Tuttavia, più di qualsiasi altro servizio AWS, ECS ha evidenziato il lock-in intrinseco alla piattaforma che molti utenti preferiscono evitare. Inoltre molti clienti enterprise utilizzano più di un cloud provider ed apprezzano la possibilità di sfruttare le stesse conoscenze tecniche e operative su più piattaforme, e Kubernetes ha indiscutibilmente il miglior set di funzionalità e la promessa di portabilità tra cloud e data center. Lo slancio di Kubernetes è arrivato al punto di costituire la posta in gioco per le aziende nella loro valutazione dei cloud provider da adottare; così AWS ha infine deciso di rilasciare EKS in GA a metà 2018, partendo in ritardo rispetto al competitor.
Questa breve parentesi di storia serve a spiegare il contesto: EKS è giovane rispetto al competitor, ma negli anni è stato comunque arricchito di moltissime funzionalità che lo rendono assolutamente all'altezza di essere configurato per reggere applicazioni in produzione.
Cluster Autoscaler, comunque, bisogna installarlo autonomamente :-)
Come configurare Cluster Autoscaler su EKS
EKS utilizza la funzionalità degli AutoScaling Group (ASG) per integrarsi con Cluster Autoscaler ed eseguire le sue richieste di aggiunta e rimozione dei nodi.
Cluster Autoscaler non misura direttamente i valori di utilizzo della CPU e della memoria per prendere una decisione di ridimensionamento. Al contrario, controlla ogni 10 secondi la presenza eventuali pod in stato pending, da cui deduce che lo scheduler non può assegnarli a un nodo a causa della capacità insufficiente del cluster.
Anche con l'aiuto dell'eccellente modulo EKS per Terraform, configurare il cluster affinché l'autoscaling funzioni richiede una serie di configurazioni che non sono out-of-the-box.
Potete trovare una configurazione completa a questo link. In questo articolo vediamo assieme solo alcuni dettagli del codice.
La parte fondamentale è la configurazione dei node group. Per il caso d'uso illustrato all'inizio dell'articolo, ho configurato due managed node group con caratteristiche diverse:
il primo node group ha un range di autoscaling più basso perché ha un utilizzo più stabile e poco soggetto a particolari oscillazioni del carico;
il secondo node group utilizza macchine con maggiori risorse computazionali per le quali si adotta un modello di pricing spot. La configurazione dell'autoscaling group indica che, in assenza di job da eseguire, non ci siano macchine accese. Ho aggiunto anche una taint che serve a far sì che su questo node group vengano eseguiti tutte e sole le applicazioni che ne fanno esplicita richiesta.
I valori indicati nel codice sono puramente illustrativi. Verificate sempre quali valori sono più adeguati per ogni specifico caso d'uso.
La configurazione fondamentale da fare è associare esplicitamente a ciascuno dei node group alcuni tag, senza i quali l'autoscaling non funziona.
locals {
name = "eks-cas"
nodegroup1_label = "group1"
nodegroup2_label = "group2"
}
eks_managed_node_groups = {
nodegroup1 = {
desired_size = 1
max_size = 2
min_size = 1
instance_types = ["t3.medium"]
capacity_type = "ON_DEMAND"
update_config = {
max_unavailable_percentage = 50
}
labels = {
role = local.nodegroup1_label
}
tags = {
"k8s.io/cluster-autoscaler/enabled" = "true"
"k8s.io/cluster-autoscaler/${local.name}" = "owned"
"k8s.io/cluster-autoscaler/node-template/label/role" = "${local.nodegroup1_label}"
}
}
nodegroup2 = {
desired_size = 0
max_size = 10
min_size = 0
instance_types = ["c5.xlarge", "c5a.xlarge", "m5.xlarge", "m5a.xlarge"]
capacity_type = "SPOT"
update_config = {
max_unavailable_percentage = 100
}
labels = {
role = local.nodegroup2_label
}
taints = [
{
key = "dedicated"
value = local.nodegroup2_label
effect = "NO_SCHEDULE"
}
]
tags = {
"k8s.io/cluster-autoscaler/enabled" = "true"
"k8s.io/cluster-autoscaler/${local.name}" = "owned"
"k8s.io/cluster-autoscaler/node-template/taint/dedicated" = "${local.nodegroup2_label}:NoSchedule"
"k8s.io/cluster-autoscaler/node-template/label/role" = "${local.nodegroup2_label}"
}
}
}
Non è finita. Questi tag devono essere presenti non solo nella configurazione dei node group, ma anche sui nodi che vengono di fatto vengono creati dall'autoscaling group su AWS (il cui lifecycle è gestito da EKS e non da Terraform), per cui va aggiunto un altro pezzo di codice:
locals {
eks_asg_tag_list_nodegroup1 = {
"k8s.io/cluster-autoscaler/enabled" : true
"k8s.io/cluster-autoscaler/${local.name}" : "owned"
"k8s.io/cluster-autoscaler/node-template/label/role" : local.nodegroup1_label
}
eks_asg_tag_list_nodegroup2 = {
"k8s.io/cluster-autoscaler/enabled" : true
"k8s.io/cluster-autoscaler/${local.name}" : "owned"
"k8s.io/cluster-autoscaler/node-template/label/role" : local.nodegroup2_label
"k8s.io/cluster-autoscaler/node-template/taint/dedicated" : "${local.nodegroup2_label}:NoSchedule"
}
}
resource "aws_autoscaling_group_tag" "nodegroup1" {
for_each = local.eks_asg_tag_list_nodegroup1
autoscaling_group_name = element(module.eks.eks_managed_node_groups_autoscaling_group_names, 0)
tag {
key = each.key
value = each.value
propagate_at_launch = true
}
}
resource "aws_autoscaling_group_tag" "nodegroup2" {
for_each = local.eks_asg_tag_list_nodegroup2
autoscaling_group_name = element(module.eks.eks_managed_node_groups_autoscaling_group_names, 1)
tag {
key = each.key
value = each.value
propagate_at_launch = true
}
}
Usiamo infine il provider Helm per Terraform per l'installazione di cluster-autoscaler:
locals {
k8s_service_account_namespace = "kube-system"
k8s_service_account_name = "cluster-autoscaler"
}
resource "helm_release" "cluster-autoscaler" {
name = "cluster-autoscaler"
namespace = local.k8s_service_account_namespace
repository = "https://kubernetes.github.io/autoscaler"
chart = "cluster-autoscaler"
version = "9.10.7"
create_namespace = false
set {
name = "awsRegion"
value = local.region
}
set {
name = "autoDiscovery.clusterName"
value = local.name
}
set {
name = "autoDiscovery.enabled"
value = "true"
}
...
}
Come testare Cluster Autoscaler? Benché nel mio caso d'uso lo scopo principale fosse eseguire dei job batch, qui userò un deployment perché è più semplice malipolarne le repliche manualmente (è quindi più utile per illustrare le funzionalità).
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.2
resources:
requests:
cpu: 1
nodeSelector:
role: "group2"
tolerations:
- key: "dedicated"
operator: "Equal"
value: "group2"
effect: "NoSchedule"
Le proprietà nodeSelector e tolerations forzano questa applicazione a girare sul nodegroup2.
Alla creazione di questo deployment, il numero di repliche è 0:
kubectl apply -f deployment.yaml
Finalmente è tutto pronto per vedere l'autoscaling all'opera!
Scale-up su EKS con Cluster Autoscaler
Per vedere in azione l'autoscaling, aumentiamo il numero di repliche del deployment:
kubectl scale deployment inflate --replicas 5
Osservazioni generali:
la configurazione dell'ASG (AWS AutoScaling Group) decide l'instance type del nodo da creare. Nella configurazione abbiamo indicato una lista di possibili instance type: la lista viene sempre scorsa in ordine, per cui, in assenza di specifici problemi sul cloud provider, verrà creata una macchina del primo tipo indicato nella lista
nel caso in cui più di un workload richieda risorse contemporaneamente (come nel mio esempio in cui ho cambiato il numero di
replicasda 0 a 5), Cluster Autoscaler utilizza una logica sequenziale: quando rileva il primo pod in stato pending, richiede la creazione di un nuovo nodo; per i successivi, verifica che sul nodo richiesto ci siano sufficienti risorse per assegnargli il pod; e prosegue così per gli altri pod fino ad esaurimento delle risorse del nodo, quando richiede quindi un ulteriore nodo. Nell'esempio specifico, poiché il nodo che viene creato è di tipoc5.xlargeed ha 4 vCPU, e poiché il container richiede l'assegnazione di 1 CPU, ed ho richiesto la creazione di 5 repliche del pod, il primo pod genererà la creazione di un nodo, i successivi due verranno assegnati al medesimo nodo, il quarto pod non avrà spazio sufficiente e genererà la creazione di un secondo nodo, ed il quinto verrà assegnato anch'esso a questo secondo nodo.
Osservazioni sui tempi di esecuzione:
- dall'esecuzione del comando di scaling passa un certo numero di secondi prima di vedere tra i log di Kubernetes la richiesta al cloud provider di modificare il
desired_sizedell'ASG. La documentazione di Cluster Autoscaler dichiara i seguenti SLO:
No more than 30 sec latency on small clusters (less than 100 nodes with up to 30 pods each), with the average latency of about 5 sec. No more than 60 sec latency on big clusters (100 to 1000 nodes), with average latency of about 15 sec.
il tempo effettivo impiegato dal cloud provider per avere il nodo up è mediamente di 40-50 secondi
nel caso in cui sia attivo il VPC CNI plugin fornito su EKS come add-on, vi è un ulteriore tempo di attesa (anche fino a 60 secondi) per istanziare una nuova Network Interface (ENI) e assegnarla al nodo come interfaccia secondaria
complessivamente, in una situazione normale, la disponibilità del nuovo nodo in modalità ready sul cluster arriva dopo la somma dei tempi descritti ai punti precedenti
Scale-down su EKS con Cluster Autoscaler
Cosa succede quando il fabbisogno di risorse computazionali diminusce?
Cluster Autoscaler verifica periodicamente se alcuni nodi sono sottoutilizzati. Un nodo viene considerato candidato alla rimozione quando si verificano tutte le seguenti condizioni:
la somma delle richieste di CPU e memoria di tutti i pod in esecuzione su questo nodo è inferiore al 50% delle risorse disponibili del nodo
tutti i pod in esecuzione sul nodo possono essere spostati su altri nodi
non ha l'annotation di scale-down disabilitato
Cluster Autoscaler si occupa di consolidare i workload su numero minimo di nodi, calcolando quali nodi candidare alla rimozione e spostando opportunamente i pod altrove per liberare risorse.
Se un nodo non è necessario (cioè non ha pod) per più di 10 minuti (il valore di default è modificabile), Cluster Autoscaler invia al cloud provider una richiesta di diminuzione del desired_size dell'ASG per rimuovere il nodo vuoto. Una volta modificato quel valore, il nodo viene escluso dal cluster e quindi terminato. Cluster Autoscaler candida alla rimozione un solo nodo non vuoto alla volta, per ridurre il rischio di non avere sufficienti risorse per far ripartire i pod.
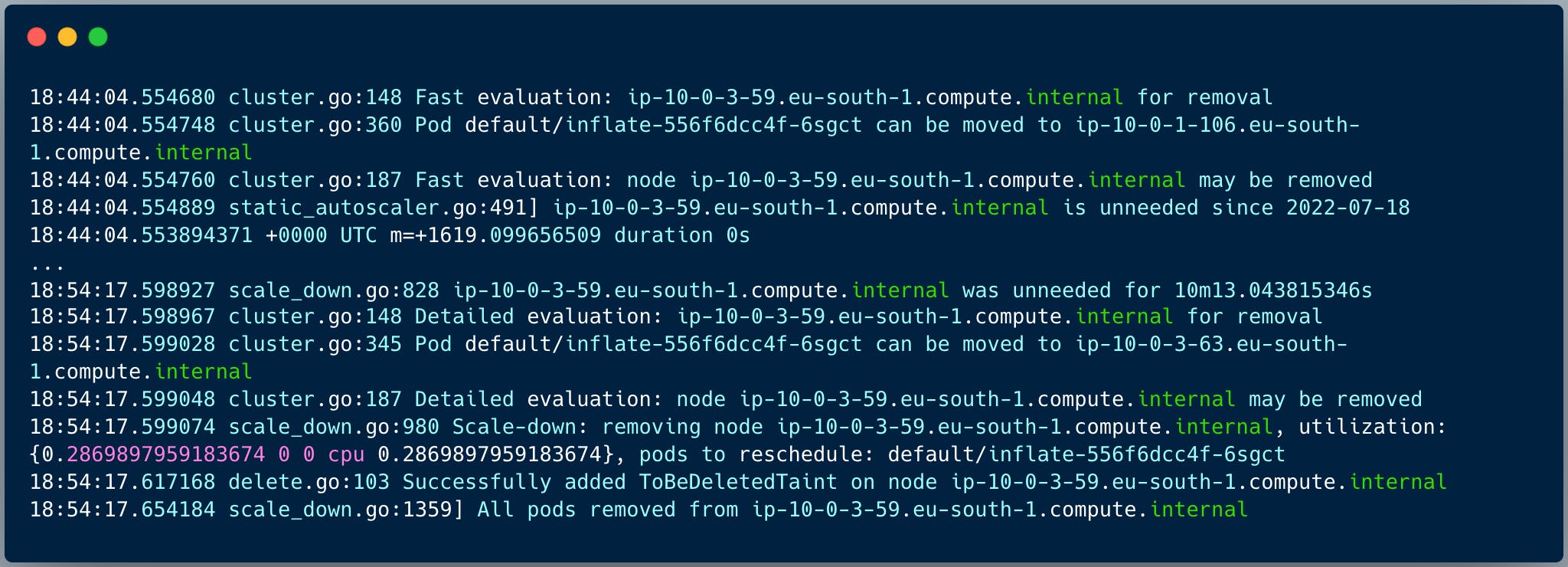
Il caso d'uso illustrato all'inizio è relativamente semplice, perché i pod in esecuzione sui nodi sono job batch, con un tempo di vita finito per definizione; quando tutti i job di un nodo hanno terminato la loro esecuzione, il nodo risulta vuoto e viene terminato (sempre dopo 10 minuti di inutilizzo) senza necessità di spostare workload.
What's new: Karpenter
Negli ultimi mesi un nuovo tool per l'autoscaling è apparso sulla scena: Karpenter. La curiosità di provarlo mi ha spinto a ripetere lo scenario utilizzando questo nuovo tool, per poter valutare eventuali benefici in termini di:
facilità di configurazione
funzionalità
velocità
Com'è andata? Potete leggere di Karpenter nell'articolo dedicato.