



Includere una macchina virtuale in una pipeline di CI/CD


If you're looking for the English version of this article, click here.
In questo articolo vedremo come eseguire uno o più step di una pipeline di CI/CD direttamente su una macchina virtuale "tradizionale".
Si pensi ad applicazioni legacy e/o proprietarie, con vincoli di licenza o di supporto, o che per qualsiasi altro motivo non si può o non si vuole reingegnerizzare, ma che sono necessarie per eseguire dei test, o delle analisi specifiche con software particolari: ad esempio, scansioni con software appartenenti al team di Security che preferisce centralizzare le informazioni in un ambiente ibrido, esecuzione di simulazioni con software come MATLAB e Simulink installati centralmente per utilizzo cross-team, e così via.
Il vincolo di utilizzo di questi software non significa che non si possano utilizzare moderne metodologie DevOps, come le pipeline di CI/CD, per lo sviluppo del codice. Come vedremo, una pipeline può prevedere uno step in cui l'esecuzione di comandi o script avviene direttamente su una macchina virtuale.
Architettura della soluzione
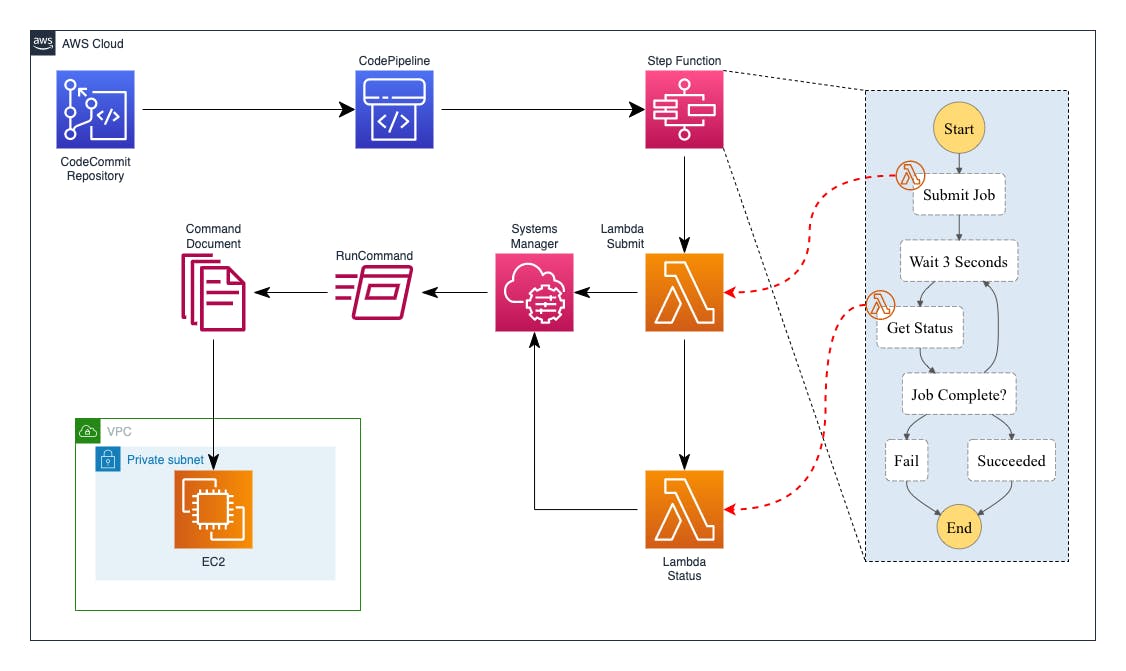
Nel caso d'uso che vediamo come esempio, la virtual machine è una AWS EC2 Windows; l'obiettivo è eseguire alcuni comandi sulla EC2 ogni volta che il mio codice viene modificato e pushato in un repository Git.
Vale la pena ricordare, comunque, che AWS Systems Manager Agent può essere installato anche su macchine on-premise o ospitate altrove. Questa soluzione è quindi estendibile a molte applicazioni anche se non sono ospitate direttamente su AWS.
Dettagli dell'architettura della soluzione:
un repository CodeCommit contiene sia il codice applicativo, sia un file JSON che include informazioni sui comandi da eseguire sulla virtual machine;
una push su questo repository triggera l'esecuzione di una CodePipeline, che a sua volta richiama una StepFunction;
la StepFunction inizializza un flusso di controllo per l'esecuzione di un comando contenuto in un SSM Document;
il Document viene "inviato" dalla StepFunction alla EC2 tramite una Lambda function;
una seconda Lambda, anch'essa controllata dalla StepFunction, verifica l'esito dell'esecuzione.
Prerequisiti
Si presuppone che la macchina virtuale sia già installata e configurata con il software da eseguire, e abbia un Instance Profile con i permessi necessari a consentire l'esecuzione di SSM Document (ed eventualmente ad accedere ai servizi AWS previsti dal caso d'uso).
Nel mio caso, le policy associate all'Instance Profile sono:
AWS Managed Policy
AmazonSSMManagedInstanceCore(per l'esecuzione di SSM Documents)AWS Managed Policy
AWSCodeCommitReadOnly(per accedere al repository del codice)custom policy per consentire
s3:PutObjectsul bucket di output
AWS Cloud Development Kit (AWS CDK)
Per la realizzazione di questa architettura ho utilizzato AWS CDK per Python.
AWS CDK è un framework di sviluppo software open source per la definizione dell'infrastruttura cloud AWS introdotto nel luglio 2019. Poiché AWS CDK utilizza CloudFormation come base, presenta tutti i vantaggi di CloudFormation consentendo di eseguire il provisioning di risorse cloud utilizzando moderni linguaggi di programmazione come Typescript, C#, Java e Python.
Se non hai familiarità con AWS CDK, puoi seguire un ottimo tutorial qui.
L'uso di AWS CDK è vantaggioso anche perché consente di scrivere una minore quantità di codice rispetto ad altri strumenti "classici" di Infrastructure as Code (nel mio esempio, le mie circa 150 righe di codice Python generano un CloudFormation di 740 righe YAML); in particolare, molti ruoli e policy IAM vengono dedotti direttamente dal framework senza bisogno di scriverli esplicitamente.
Puoi trovare l'esempio completo a questo link.
SSM Document
Per cominciare a sviluppare la mia soluzione, creo innanzi tutto un SSM Document per la mia EC2 Windows, che costituisce lo script che deve essere eseguito sulla virtual machine:
schemaVersion: "2.2"
description: "Example document"
parameters:
Message:
type: "String"
description: "Message to write"
OutputBucket:
type: "String"
description: "Bucket to save output"
CodeRepository:
type: "String"
description: "Git repository to clone"
mainSteps:
- action: "aws:runPowerShellScript"
name: "SampleStep"
precondition:
StringEquals:
- platformType
- Windows
inputs:
timeoutSeconds: "60"
runCommand:
- Import-Module AWSPowerShell
- Write-Host "Create temp dir"
- $tempdir=$(-join ((48..57) + (97..122) | Get-Random -Count 32 | % {[char]$_}))
- New-item "$env:temp\$tempdir" -ItemType Directory
- Write-Host "Cloning repository"
- "git clone {{CodeRepository}} $tempdir"
- $fname = $(((get-date).ToUniversalTime()).ToString("yyyyMMddTHHmmssZ"))
- Write-Host "Writing file on S3"
- "Write-S3Object -BucketName {{OutputBucket}} -Key ($fname + '.txt') -Content {{Message}}"
- Write-Host "Removing temp dir"
- Remove-Item -path $tempdir -Recurse -Force -EA SilentlyContinue
- Write-Host "All done!"
Questo script di esempio si aspetta 3 parametri: il repository Git da clonare, il messaggio da scrivere nel file di output, e il bucket S3 dove salvare questo file di output; e utilizza poi questi parametri con i comandi da eseguire. Naturalmente si tratta di un esempio molto semplice, che può essere modificato a seconda delle esigenze.
Utilizzo questo file YAML direttamente nel mio codice Python per creare il Document su AWS SSM:
with open("ssm/windows.yml") as openFile:
documentContent = yaml.load(openFile, Loader=yaml.FullLoader)
cfn_document = ssm.CfnDocument(self, "MyCfnDocument",
content=documentContent,
document_format="YAML",
document_type="Command",
name="pipe-sfn-ec2Win-GitS3",
update_method="NewVersion",
target_type="/AWS::EC2::Instance"
)
Lambda
Creo il repository CodeCommit dove salverò il codice applicativo, il bucket S3 per la scrittura dei risultati delle elaborazioni, e quindi le due Lambda:
repo = codecommit.Repository(self, "pipe-sfn-ec2Repo",
repository_name="pipe-sfn-ec2-repo"
)
output_bucket = s3.Bucket(self, 'ExecutionOutputBucket')
submit_lambda = _lambda.Function(self, 'submitLambda',
handler='lambda_function.lambda_handler',
runtime=_lambda.Runtime.PYTHON_3_9,
code=_lambda.Code.from_asset('lambdas/submit'),
environment={
"OUTPUT_BUCKET": output_bucket.bucket_name,
"SSM_DOCUMENT": cfn_document.name,
"CODE_REPOSITORY": repo.repository_clone_url_http
})
status_lambda = _lambda.Function(self, 'statusLambda',
handler='lambda_function.lambda_handler',
runtime=_lambda.Runtime.PYTHON_3_9,
code=_lambda.Code.from_asset('lambdas/status'))
Come si vede, la Lambda "submit" ha 3 variabili d'ambiente che serviranno come parametri per i comandi da eseguire sulla virtual machine. Anche il codice delle Lambda è in Python:
import boto3
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
ssm_client = boto3.client('ssm')
document_name = os.environ["SSM_DOCUMENT"]
output_bucket = os.environ["OUTPUT_BUCKET"]
code_repository = os.environ["CODE_REPOSITORY"]
def lambda_handler(event, context):
logger.debug(event)
instance_id = event["instance_id"]
message = event["message"]
response = ssm_client.send_command(
InstanceIds=[instance_id],
DocumentName=document_name,
Parameters={
"Message": [message],
"OutputBucket": [output_bucket],
"CodeRepository": [code_repository]})
logger.debug(response)
command_id = response['Command']['CommandId']
data = {
"command_id": command_id,
"instance_id": instance_id
}
return data
L'output di questa prima Lambda "submit" diventa l'input della seconda Lambda "status", che controlla lo stato dell'esecuzione appena lanciata:
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
ssm_client = boto3.client('ssm')
def lambda_handler(event, context):
instance_id = event['Payload']['instance_id']
command_id = event['Payload']['command_id']
logger.debug(instance_id)
logger.debug(command_id)
response = ssm_client.get_command_invocation(CommandId=command_id, InstanceId=instance_id)
logger.debug(response)
execution_status = response['StatusDetails']
logger.debug(execution_status)
if execution_status == "Success":
return {"status": "SUCCEEDED", "event": event}
elif execution_status in ('Pending', 'InProgress', 'Delayed'):
data = {
"command_id": command_id,
"instance_id": instance_id,
"status": "RETRY",
"event": event
}
return data
else:
return {"status": "FAILED", "event": event}
L'output di questa Lambda "status" determinerà il flusso della StepFunction: se l'esecuzione del Document su SSM risulta completata, la StepFunction terminerà con uno stato corrispondente (Success o Failed); se invece l'esecuzione è ancora in progress, il flusso della StepFunction prevederà un tempo di attesa e quindi la riesecuzione della Lambda per una nuova verifica dello stato.
Devo anche attribuire i permessi necessari. La prima Lambda deve poter lanciare l'esecuzione del SSM Document sulla EC2; la seconda Lambda ha invece bisogno dei permessi per consultare le esecuzioni SSM:
ec2_arn = Stack.of(self).format_arn(
service="ec2",
resource="instance",
resource_name="*"
)
cfn_document_arn = Stack.of(self).format_arn(
service="ssm",
resource="document",
resource_name=cfn_document.name
)
ssm_arn = Stack.of(self).format_arn(
service="ssm",
resource="*"
)
submit_lambda.add_to_role_policy(iam.PolicyStatement(
resources=[cfn_document_arn, ec2_arn],
actions=["ssm:SendCommand"]
))
status_lambda.add_to_role_policy(iam.PolicyStatement(
resources=[ssm_arn],
actions=["ssm:GetCommandInvocation"]
))
Si noti che questi sono gli unici permessi che ho scritto esplicitamente nel mio codice, poiché si tratta di capabilities derivanti dalla logica interna delle Lambda. Tutti gli altri permessi (ad esempio, lettura del repository CodeCommit, esecuzione della StepFunction, trigger della CodePipeline, ecc.) sono implicitamente dedotti dal framework CDK, abbreviando enormemente la scrittura del mio codice IaC.
StepFunction
Il flusso della StepFunction è mostrato nel seguente schema:
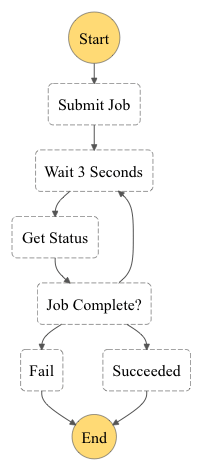
La sua definizione è la seguente:
submit_job = _aws_stepfunctions_tasks.LambdaInvoke(
self, "Submit Job",
lambda_function=submit_lambda
)
wait_job = _aws_stepfunctions.Wait(
self, "Wait 10 Seconds",
time=_aws_stepfunctions.WaitTime.duration(
Duration.seconds(10))
)
status_job = _aws_stepfunctions_tasks.LambdaInvoke(
self, "Get Status",
lambda_function=status_lambda
)
fail_job = _aws_stepfunctions.Fail(
self, "Fail",
cause='AWS SSM Job Failed',
error='Status Job returned FAILED'
)
succeed_job = _aws_stepfunctions.Succeed(
self, "Succeeded",
comment='AWS SSM Job succeeded'
)
definition = submit_job.next(wait_job)\
.next(status_job)\
.next(_aws_stepfunctions.Choice(self, 'Job Complete?')
.when(_aws_stepfunctions.Condition.string_equals('$.Payload.status', 'FAILED'), fail_job)
.when(_aws_stepfunctions.Condition.string_equals('$.Payload.status', 'SUCCEEDED'), succeed_job)
.otherwise(wait_job))
sfn = _aws_stepfunctions.StateMachine(
self, "StateMachine",
definition=definition,
timeout=Duration.minutes(5)
)
CodePipeline
In questo esempio, per semplicità di esposizione, definisco la mia pipeline creando due soli step, quello di source e quello di esecuzione della StepFunction:
pipeline = codepipeline.Pipeline(self, "pipe-sfn-ec2Pipeline",
pipeline_name="pipe-sfn-ec2Pipeline",
cross_account_keys=False
)
source_output = codepipeline.Artifact("SourceArtifact")
source_action = codepipeline_actions.CodeCommitSourceAction(
action_name="CodeCommit",
repository=repo,
branch="main",
output=source_output
)
step_function_action = codepipeline_actions.StepFunctionInvokeAction(
action_name="Invoke",
state_machine=sfn,
state_machine_input=codepipeline_actions.StateMachineInput.file_path(source_output.at_path("abc.json"))
)
pipeline.add_stage(
stage_name="Source",
actions=[source_action]
)
pipeline.add_stage(
stage_name="StepFunctions",
actions=[step_function_action]
)
Richiamo l'attenzione sulla definizione di state_machine_input: in questo codice ho indicato che i parametri di input della StepFunction devono essere letti dal file abc.json contenuto direttamente nel repository CodeCommit.
Esecuzione
Per testare la soluzione, pusho nel repository il file abc.json con il seguente contenuto:
{
"instance_id": "i-1234567890abcdef",
"message": "aSampleMessage"
}
In questo modo, lo sviluppatore che scrive il proprio codice e che deve eseguire i suoi comandi sulla virtual machine, può indicare sia la macchina sia i parametri dell'esecuzione.
E' tutto qui! Una volta effettuato il push, la pipeline parte automaticamente, scarica il codice dal repository e lancia la StepFunction:
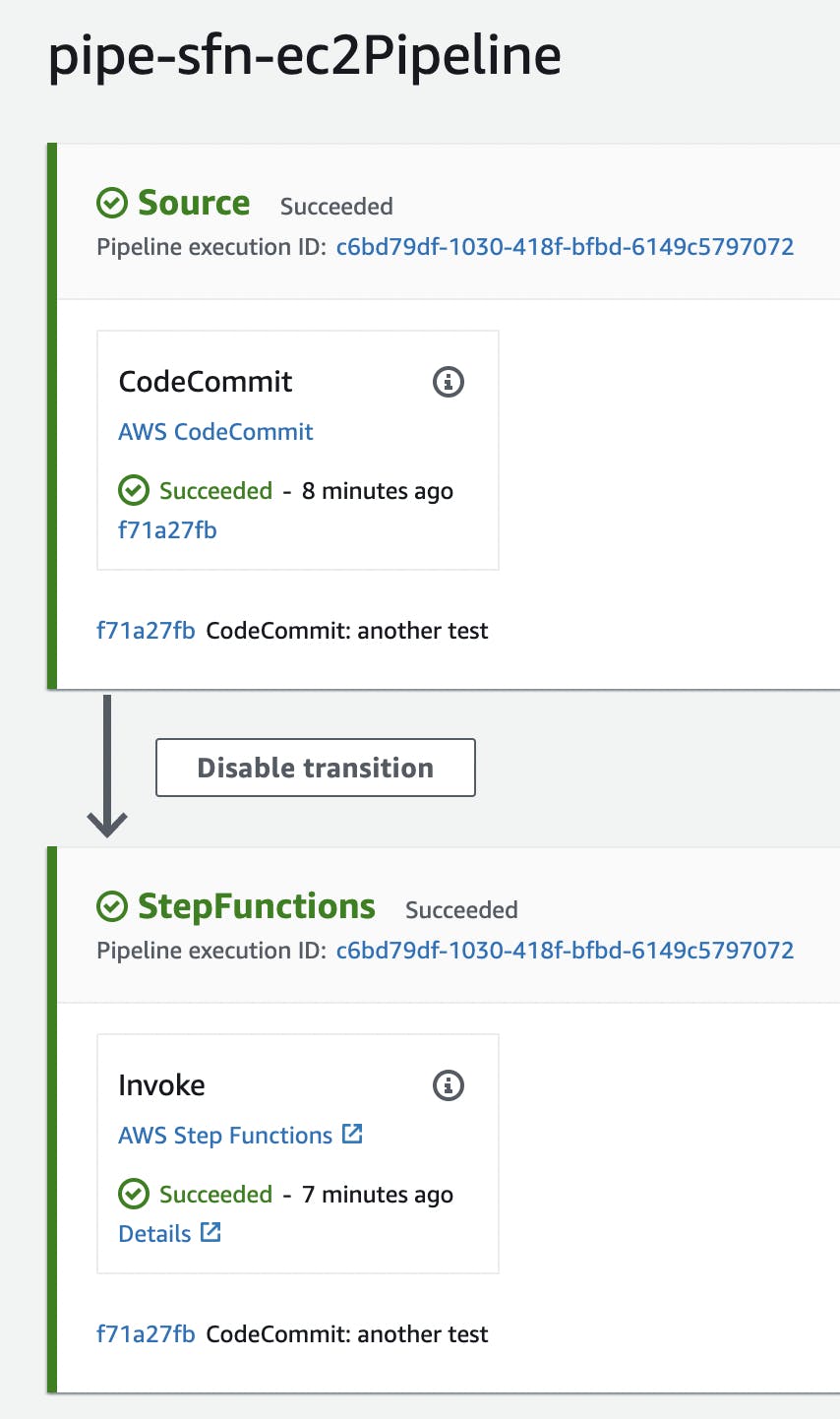
E' possibile consultare il flusso dell'esecuzione della StepFunction:
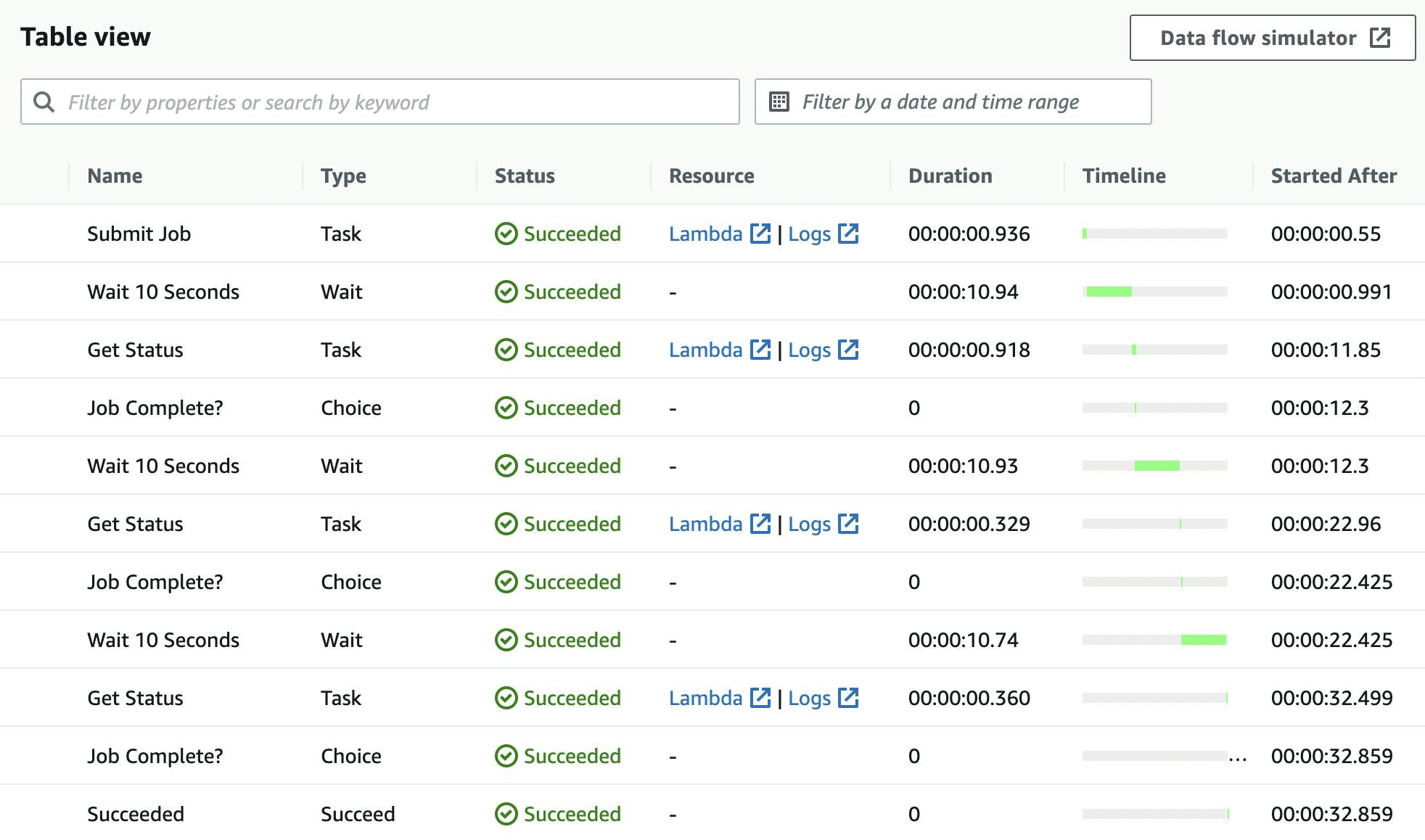
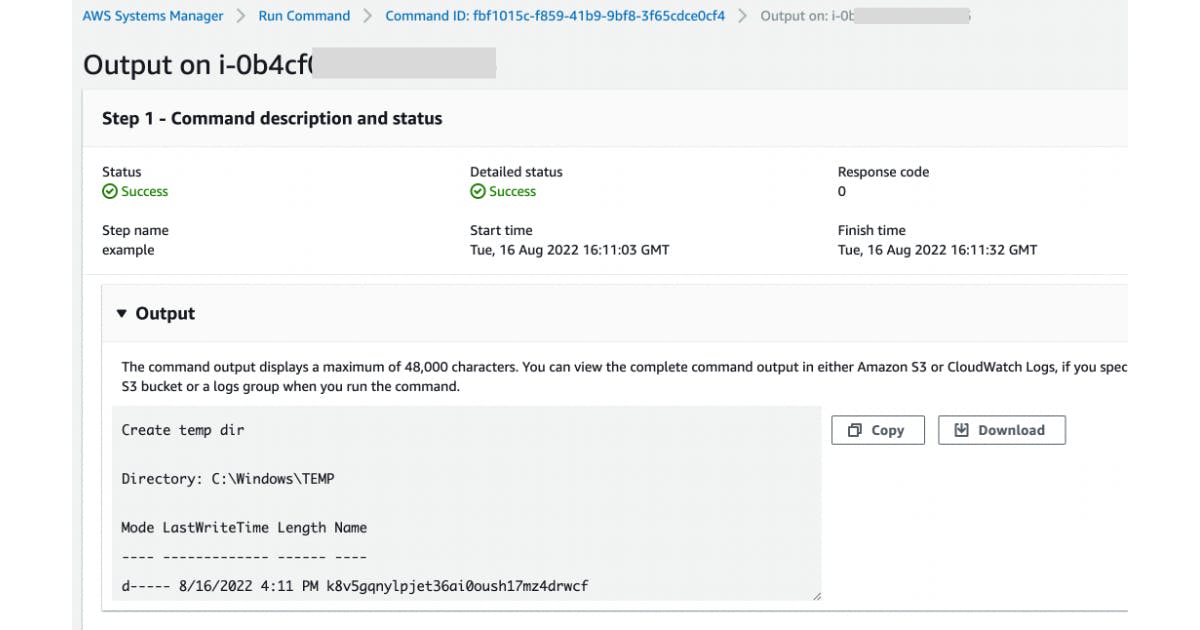
Si può anche consultare l'esecuzione del SSM Document:
Considerazioni
Avere dei vincoli, imposti da scelte organizzative o da alcuni tipi di software, è una situazione molto comune soprattutto nelle grandi aziende: ciò non deve scoraggiare nell'introduzione di metodologie e tecnologie moderne, perché quest'ultime consentono di inventare soluzioni per (quasi) qualsiasi integrazione.
L'introduzione nella pipeline di una StepFunction, che può sembrare una sovra ingegnerizzazione in casi in cui i comandi richiedono pochi secondi per essere eseguiti su una macchina virtuale, si rivela in realtà indispensabile quando invece tale esecuzione ha dei tempi relativamente lunghi.
L'utilizzo di AWS CDK abbrevia molto i tempi di scrittura del codice, a patto di avere un po' di familiarità con uno dei linguaggi di programmazione supportati.