
Automated Mass Tagging in AWS Across Accounts and Organizations

Tagging strategy: easier said...
In the expansive world of AWS, tagging resources stands out as both a straightforward task and an essential one. On the surface, it's about assigning a label, a seemingly simple action. Yet, the implications of this action are profound. Tags are not just mere identifiers; they're pivotal tools in organizing, managing, and optimizing your cloud environment, because they cater to a range of organizational needs, such as:
Expense Tracking: for instance, with Cost Allocation Tags, you can monitor specific costs tied to a particular project or department.
Infrastructure Automation: tags can trigger Automated Infrastructure Activities. Think of an instance that's tagged as 'development' being automatically shut down outside of working hours to save costs.
Project Phases: with Workload Lifecycle tags, you can easily identify whether a particular resource is in the 'testing', 'development', or 'production' phase.
Issue Resolution: incident management tags can help in quickly identifying resources that might be affected during an outage or incident.
Maintenance: update management tags can indicate when a resource was last patched or updated, ensuring timely maintenance.
Operational Insights: for a clear view of your operations, Operational Observability tags can denote the health or status of resources.
Data Protection: risk and security management tags can highlight resources that contain sensitive data, ensuring they have tighter security controls.
Access Management: identity and access tags can dictate who within your organization can access specific resources, reinforcing security protocols.
A well-defined tagging strategy is paramount. AWS itself recognizes the significance of this and has published an extensive whitepaper detailing best practices and guidelines. This strategy isn't just about knowing what to tag, but understanding the 'why' and 'how' behind each tag.
...than done
So, once we've established our tagging strategy, is it smooth sailing from there? Well, as the saying goes, "easier said than done." Indeed, a strategy is only as good as its execution plan. A comprehensive strategy must be paired with a pragmatic action plan detailing its implementation.
From our list of tagging use cases, one aspect becomes abundantly clear: tags, while seemingly simple tools, cater to a myriad of distinct purposes. These purposes, in turn, address the needs of diverse teams within an organization. Whether it's Finance, Operations, Security, or Development teams, each has its unique requirements. These teams might possess different skill sets, operate on varying timelines, and even employ distinct tools for their tagging activities. The challenge then is coordination: how do these teams work in tandem without stepping on each other's toes?
Organizational complexity
To truly grasp the intricacies of tagging, let's delve into a real-world scenario I encountered. In this setup, there's a team, aptly named "Cloud Center", responsible for managing the AWS Organizations. Their tasks encompass creating, overseeing, and auditing the AWS accounts affiliated with the organization.
Within this Organization, there are several Organizational Units (OUs) mirroring the company's internal structure. Each OU houses multiple projects, and each project might have separate accounts for development, testing, and production.
Each OU is backed by a Platform Team, providing project teams with essential tools, such as CI/CD pipelines and Infrastructure as Code (IaC) execution tools like Terraform. Then, every project has a separate team, which is diverse, comprising roles like backend engineers, DevOps specialists, QAs, and more. Notably, many team members are often consultants or contractors dedicated to specific projects rather than company employees.
Additionally, there are shared OUs and accounts dedicated to operational services, like networking, Transit Gateway, Network Firewall, and DNS, or security-centric tasks: each of these is managed by a different team.
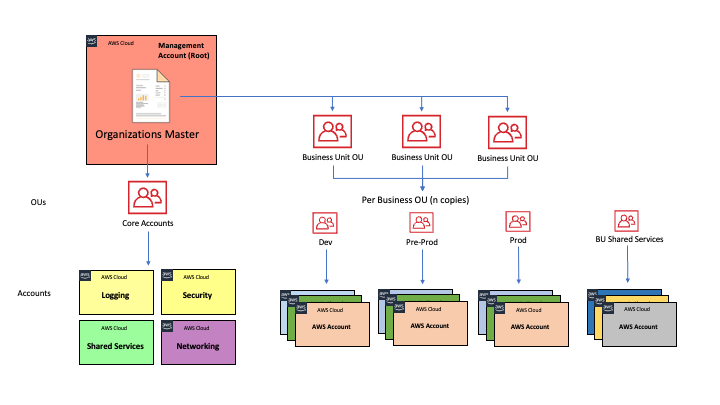
On top of all that, this Organization belongs to a larger corporate group. At the group level, there's a need to monitor the spending of each subsidiary company. This requires data extraction from each Organization, necessitating the tagging of AWS accounts themselves, with unique labels and values consistent across the entire corporate group.
The mass-tagging hierarchy
In such a multifaceted environment, expecting every individual to simply read a tagging strategy manual and apply it flawlessly is wishful thinking. Each team has its tagging objectives aligned with its goals. However, keeping track of everyone's tagging needs would be a Herculean task. While enforcing a Tagging Policy can provide some structure, manually reconciling the requirements of so many teams would be a colossal drain on time and resources.
The reality of the matter is that tags, in many instances, aren't particularly volatile entities. In an ideal setup, they act as labels assigned during the creation of a resource. Once in place, these tags seldom change, except for specific use cases. Given this nature, it's counterproductive to burden individuals with a task that, with the right precautions, can be seamlessly automated. After all, machines are inherently better suited for repetitive and mundane tasks than humans.
This realization led to the adoption of a multi-tiered mass-tagging strategy. Each "tier" or "level" employed a recurring Lambda function to tag all resources under its purview. Care was taken to ensure that tags from one level didn't overwrite or remove those from another.
Cloud Center Command
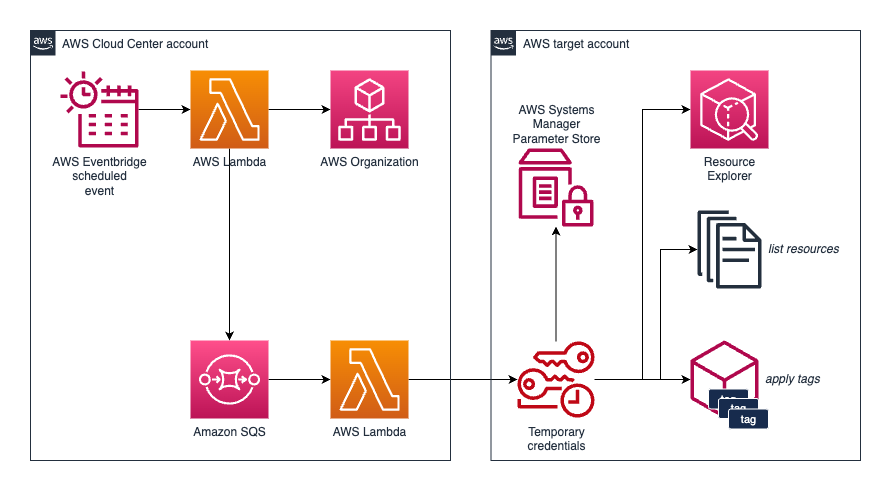
At the topmost tier, the Cloud Center took on the responsibility of tagging AWS accounts directly. This was primarily for billing, finance, and cost allocation purposes. They utilized tags that were globally unique within the corporate group, along with additional tags indicating the OU, project, and environment specifics. Here's how the process was streamlined:
every night, an EventBridge-scheduled Lambda function would activate. This function would:
read all the tags (both key and value) for each account
def list_accounts(): existing_accounts = [ account for accounts in _org_client.get_paginator("list_accounts").paginate() for account in accounts['Accounts'] ] return existing_accounts def get_account_tags( account_id): formatted_tags = _org_client.list_tags_for_resource( ResourceId=account_id) return formatted_tags def handler(event, context): for account in list_accounts(): account_id = account.get('Id') try: tags = get_account_tags(account_id) except Exception as ce: logger.error( f'Exception retrieving tags in Organization for account {account_id}: {ce}') continuecreate a message for each account in an SQS queue
sqs.send_message( QueueUrl=sqs_queue_url, DelaySeconds=15, MessageAttributes={ 'Account': { 'DataType': 'String', 'StringValue': account_id }, 'Tags': { 'DataType': 'String', 'StringValue': json.dumps(response_json) }, 'Region': { 'DataType': 'String', 'StringValue': reg } }, MessageBody=( f'Tag value for account {account_id} in region {reg}' ) )
each message in the queue would then trigger a second Lambda function. This function would:
read the message content
for record in event['Records']: account_id = record['messageAttributes']['Account']['stringValue'] tags_raw = record['messageAttributes']['Tags']['stringValue'] reg = record['messageAttributes']['Region']['stringValue'] receipt_handle = record['receiptHandle'] tags = json.loads(tags_raw)['Tags']assume an IAM role in the target account
save the tag list in an SSM parameter
list resources to be tagged using the
resourcegroupstaggingapiclient = create_boto3_client(account_id, 'resourcegroupstaggingapi', assume_role(account_id), reg) map = client.get_resources(ResourcesPerPage=50) list = get_resources_to_tag(map['ResourceTagMappingList'], tagkey, tagvalue) [...] def get_resources_to_tag(map, tagkey, tagvalue): resourcelist = [] for resource in map: logger.debug(f'Resource: {resource}') if resource['ResourceARN'].startswith('arn:aws:cloudformation'): logger.debug( f'Resource {resource} is a cloudformation stack, we do not need to tag it') continue to_be_tagged = True for tag in resource['Tags']: if tag['Key'] == tagkey and tag['Value'] == tagvalue: to_be_tagged = False logger.debug( f'Found tag {tagkey} with value {tagvalue} in resource, no need to retag') break if to_be_tagged == True: logger.debug( f'NOT FOUND tag {tagkey} with value {tagvalue} in resource, need to tag') resourcelist.append(resource['ResourceARN']) return resourcelistfinally, apply the tags.
This approach ensured that the Cloud Center team maintained tags in a centralized manner, eliminating the need for disparate synchronization efforts.
Platform Team Playbook
The second "tier" in this tagging hierarchy is occupied by the Platform Teams of each OU, and their approach mirrors that of the Cloud Center, albeit with some tailored modifications.
In the case of the Platform Teams, their management account has read delegation over the Organization. The nightly process for them unfolds as follows:
Account Listing from Organization: Triggered by EventBridge at a different time than the Cloud Center's process, a Lambda function initiates and reads the list of accounts specific to its OU from the Organization.
Mass Tagging (If Necessary): If the Platform Team has its specific tags to apply, it employs a mass-tagging approach identical to the Cloud Center's. It's worth noting that not all Platform Teams have this requirement. Some use this technique to assign tags that indicate, for instance, which EBS volumes need backups or which non-production EC2 instances can be shut down during nights and weekends.
Terraform Pipeline Integration: Given that these Platform Teams provide project teams with Terraform execution pipelines, they adopt a methodology (detailed in this article) that dynamically instructs the AWS provider in Terraform to "ignore" certain tags. This list of "ignored" tags is a merger of the Cloud Center's tags (read from the SSM Parameter saved by the Cloud Center's Lambda function) and their own.
provider "aws" { ignore_tags { keys = ["cost_centre","environment","territory","service","billing_team"] } [...] }
Project Team Precision
The final tier in this tagging hierarchy is the project teams. Their primary focus is on their specific projects, and they shouldn't be burdened with the complexities of the overarching tagging strategy. While transparency is essential, and indeed, tag information is openly shared (given that tags are visible and not shrouded in secrecy), it's not the project teams' responsibility to manage or be overly concerned with them.
These teams have the liberty to add project-specific tags using their primary tool, Terraform. However, there's a catch: they can only use Terraform through the pipeline provided by their respective Platform Team. This constraint is in place because individual user accounts have very limited permissions, typically read-only. This restriction ensures that resources are not proliferated haphazardly without version control on Git, avoiding the pitfalls of ClickOps.
The beauty of the pipeline's design is its runtime instruction to Terraform to ignore specific tags. This feature acts as a safeguard. Even if a team member inadvertently adds a tag in Terraform that matches an existing tag but with a different value, the pipeline ensures that the original value remains untouched and the new value is disregarded.
Making Sense of the Tagging Puzzle
Tagging in AWS might seem like a small task, but as we've seen, it's a big deal. Getting from a plan on paper to actually tagging everything right is no walk in the park. But with a good system in place and everyone on the same page, it becomes a lot easier.
What's the main lesson here? Keep things automated and work together. Machines are great at repetitive tasks, so let's let them handle that. And when teams collaborate, the whole tagging process becomes smoother and more efficient.



