



Breaking Down Barriers: Using CI/CD with Constrained or Legacy Software


There is an Italian version of this article; if you'd like to read it click here.
In this article, we will see how to execute one or more steps of a CI/CD pipeline directly on a "traditional" virtual machine.
Think of legacy and/or proprietary applications, with license or support constraints, or that you cannot or do not want to re-engineer for any other reason, but which are necessary to perform specific tests or analyses with particular software: for example, scans with software belonging to the security team that prefers to centralize information in a hybrid environment, running simulations with software such as MATLAB and Simulink installed centrally for cross-team use, and so on.
The constraint of using these software does not mean that modern DevOps methodologies, such as CI/CD pipelines, cannot be used for code development. As we will see, a pipeline can include a step in which the execution of commands or scripts takes place directly on a virtual machine.
Solution architecture
In today's use case, the virtual machine is an AWS EC2 Windows; the goal is to run some commands on the EC2 every time my code is modified and pushed into a Git repository.
It is worth mentioning, however, that the AWS Systems Manager Agent can also be installed on on-premise or hosted elsewhere machines. This solution is therefore extendable to many applications even if they are not hosted directly on AWS.
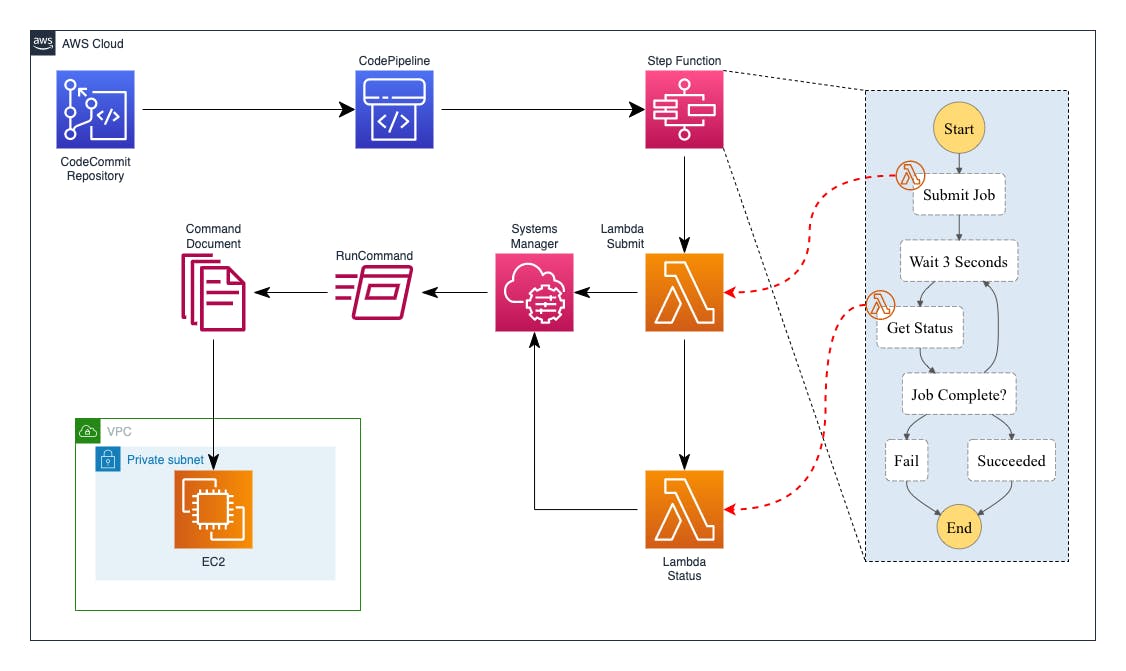
Solution architecture details:
a CodeCommit repository contains both the application code and a JSON file that includes information about the commands to be executed on the virtual machine;
a push on this repository will trigger the execution of a CodePipeline, which in turn calls a StepFunction;
the StepFunction initializes a workflow to execute a command specified in an SSM Document;
the Document is "sent" from the StepFunction to the virtual machine through a Lambda function;
a second Lambda, also controlled by the StepFunction, verifies the outcome of the execution.
Prerequisites
The virtual machine is already installed and configured with the software to run, and it has an Instance Profile with the necessary permissions to allow the SSM Document to run (and possibly to access the AWS services needed by the use case).
In my case, the policies associated with the Instance Profile are:
AWS Managed Policy
AmazonSSMManagedInstanceCore(to be managed by SSM)AWS Managed Policy
AWSCodeCommitReadOnly(to access the code repository)custom policy to allow
s3:PutObjecton the output bucket
AWS Cloud Development Kit (AWS CDK)
To create this architecture, I used AWS CDK for Python.
AWS CDK is an open-source software development framework for defining the AWS cloud infrastructure introduced in July 2019. Since AWS CDK uses CloudFormation as a foundation, it has all the benefits of CloudFormation by allowing you to provision cloud resources using modern programming languages such as Typescript, C#, Java and Python.
If you are not familiar with AWS CDK, you can follow a great tutorial here.
Using AWS CDK is also advantageous because it allows you to write less code than other "classic" Infrastructure as Code tools (in my example, my approximately 150 lines of Python code generate 740 CloudFormation YAML lines); in particular, many IAM roles and policies are deduced directly from the framework without having to write them explicitly.
You can find the complete example at this link.
SSM Document
To start developing my solution, I first create an SSM Document for my EC2 Windows, which is the script that needs to be run on the virtual machine:
schemaVersion: "2.2"
description: "Example document"
parameters:
Message:
type: "String"
description: "Message to write"
OutputBucket:
type: "String"
description: "Bucket to save output"
CodeRepository:
type: "String"
description: "Git repository to clone"
mainSteps:
- action: "aws:runPowerShellScript"
name: "SampleStep"
precondition:
StringEquals:
- platformType
- Windows
inputs:
timeoutSeconds: "60"
runCommand:
- Import-Module AWSPowerShell
- Write-Host "Create temp dir"
- $tempdir=$(-join ((48..57) + (97..122) | Get-Random -Count 32 | % {[char]$_}))
- New-item "$env:temp\$tempdir" -ItemType Directory
- Write-Host "Cloning repository"
- "git clone {{CodeRepository}} $tempdir"
- $fname = $(((get-date).ToUniversalTime()).ToString("yyyyMMddTHHmmssZ"))
- Write-Host "Writing file on S3"
- "Write-S3Object -BucketName {{OutputBucket}} -Key ($fname + '.txt') -Content {{Message}}"
- Write-Host "Removing temp dir"
- Remove-Item -path $tempdir -Recurse -Force -EA SilentlyContinue
- Write-Host "All done!"
This example script has 3 parameters: the Git repository to clone, the message to write to the output file, and the S3 bucket to save that file; and then it uses these parameters with the commands to execute. Of course, this is a straightforward example, which can be modified as needed.
I use this YAML file directly in my Python code to create the Document on AWS SSM:
with open("ssm/windows.yml") as openFile:
documentContent = yaml.load(openFile, Loader=yaml.FullLoader)
cfn_document = ssm.CfnDocument(self, "MyCfnDocument",
content=documentContent,
document_format="YAML",
document_type="Command",
name="pipe-sfn-ec2Win-GitS3",
update_method="NewVersion",
target_type="/AWS::EC2::Instance"
)
Lambda
I create the CodeCommit repository where I will save the application code, the S3 bucket to write the processing results, and then the two Lambdas:
repo = codecommit.Repository(self, "pipe-sfn-ec2Repo",
repository_name="pipe-sfn-ec2-repo"
)
output_bucket = s3.Bucket(self, 'ExecutionOutputBucket')
submit_lambda = _lambda.Function(self, 'submitLambda',
handler='lambda_function.lambda_handler',
runtime=_lambda.Runtime.PYTHON_3_9,
code=_lambda.Code.from_asset('lambdas/submit'),
environment={
"OUTPUT_BUCKET": output_bucket.bucket_name,
"SSM_DOCUMENT": cfn_document.name,
"CODE_REPOSITORY": repo.repository_clone_url_http
})
status_lambda = _lambda.Function(self, 'statusLambda',
handler='lambda_function.lambda_handler',
runtime=_lambda.Runtime.PYTHON_3_9,
code=_lambda.Code.from_asset('lambdas/status'))
As you can see, the Lambda "submit" has 3 environment variables that will serve as parameters for the commands to be executed on the virtual machine. The Lambda code is also in Python:
import boto3
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
ssm_client = boto3.client('ssm')
document_name = os.environ["SSM_DOCUMENT"]
output_bucket = os.environ["OUTPUT_BUCKET"]
code_repository = os.environ["CODE_REPOSITORY"]
def lambda_handler(event, context):
logger.debug(event)
instance_id = event["instance_id"]
message = event["message"]
response = ssm_client.send_command(
InstanceIds=[instance_id],
DocumentName=document_name,
Parameters={
"Message": [message],
"OutputBucket": [output_bucket],
"CodeRepository": [code_repository]})
logger.debug(response)
command_id = response['Command']['CommandId']
data = {
"command_id": command_id,
"instance_id": instance_id
}
return data
This first Lambda "submit" output becomes the second Lambda "status" input: it checks the status of the just started execution:
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
ssm_client = boto3.client('ssm')
def lambda_handler(event, context):
instance_id = event['Payload']['instance_id']
command_id = event['Payload']['command_id']
logger.debug(instance_id)
logger.debug(command_id)
response = ssm_client.get_command_invocation(CommandId=command_id, InstanceId=instance_id)
logger.debug(response)
execution_status = response['StatusDetails']
logger.debug(execution_status)
if execution_status == "Success":
return {"status": "SUCCEEDED", "event": event}
elif execution_status in ('Pending', 'InProgress', 'Delayed'):
data = {
"command_id": command_id,
"instance_id": instance_id,
"status": "RETRY",
"event": event
}
return data
else:
return {"status": "FAILED", "event": event}
This Lambda "status" output will determine the StepFunction workflow: if the SSM Document execution is completed, the StepFunction will terminate with a corresponding status (Success or Failed); instead, if the execution is still in progress, the StepFunction will wait some time and then will re-execute the Lambda again for a new status check.
I also need to grant the necessary permissions. The first Lambda must be able to launch the execution of the SSM Document on EC2; the second Lambda instead needs the permissions to consult the SSM executions:
ec2_arn = Stack.of(self).format_arn(
service="ec2",
resource="instance",
resource_name="*"
)
cfn_document_arn = Stack.of(self).format_arn(
service="ssm",
resource="document",
resource_name=cfn_document.name
)
ssm_arn = Stack.of(self).format_arn(
service="ssm",
resource="*"
)
submit_lambda.add_to_role_policy(iam.PolicyStatement(
resources=[cfn_document_arn, ec2_arn],
actions=["ssm:SendCommand"]
))
status_lambda.add_to_role_policy(iam.PolicyStatement(
resources=[ssm_arn],
actions=["ssm:GetCommandInvocation"]
))
Please note that these are the only permissions I have explicitly written in my code, as these are capabilities deriving from Lambdas' internal logic. All other permissions (for example, reading the CodeCommit repository, executing the StepFunction, triggering the CodePipeline, etc.) are implicitly inferred from the CDK framework, greatly shortening the writing of my IaC code.
StepFunction
The StepFunction workflow is shown in the following diagram:
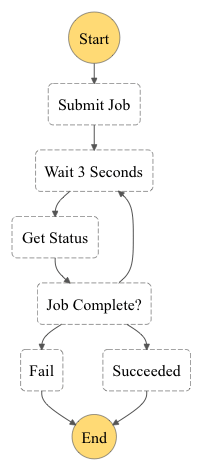
This is its definition:
submit_job = _aws_stepfunctions_tasks.LambdaInvoke(
self, "Submit Job",
lambda_function=submit_lambda
)
wait_job = _aws_stepfunctions.Wait(
self, "Wait 10 Seconds",
time=_aws_stepfunctions.WaitTime.duration(
Duration.seconds(10))
)
status_job = _aws_stepfunctions_tasks.LambdaInvoke(
self, "Get Status",
lambda_function=status_lambda
)
fail_job = _aws_stepfunctions.Fail(
self, "Fail",
cause='AWS SSM Job Failed',
error='Status Job returned FAILED'
)
succeed_job = _aws_stepfunctions.Succeed(
self, "Succeeded",
comment='AWS SSM Job succeeded'
)
definition = submit_job.next(wait_job)\
.next(status_job)\
.next(_aws_stepfunctions.Choice(self, 'Job Complete?')
.when(_aws_stepfunctions.Condition.string_equals('$.Payload.status', 'FAILED'), fail_job)
.when(_aws_stepfunctions.Condition.string_equals('$.Payload.status', 'SUCCEEDED'), succeed_job)
.otherwise(wait_job))
sfn = _aws_stepfunctions.StateMachine(
self, "StateMachine",
definition=definition,
timeout=Duration.minutes(5)
)
CodePipeline
In this example, for the sake of simplicity, I define my pipeline by creating only two steps, the source one and the StepFunction execution one:
pipeline = codepipeline.Pipeline(self, "pipe-sfn-ec2Pipeline",
pipeline_name="pipe-sfn-ec2Pipeline",
cross_account_keys=False
)
source_output = codepipeline.Artifact("SourceArtifact")
source_action = codepipeline_actions.CodeCommitSourceAction(
action_name="CodeCommit",
repository=repo,
branch="main",
output=source_output
)
step_function_action = codepipeline_actions.StepFunctionInvokeAction(
action_name="Invoke",
state_machine=sfn,
state_machine_input=codepipeline_actions.StateMachineInput.file_path(source_output.at_path("abc.json"))
)
pipeline.add_stage(
stage_name="Source",
actions=[source_action]
)
pipeline.add_stage(
stage_name="StepFunctions",
actions=[step_function_action]
)
I draw your attention to the state_machine_input definition: in this code, I have indicated that the StepFunction input parameters must be read from the abc.json file contained directly in the CodeCommit repository.
Execution
To test the solution, push the abc.json file with the following content into the repository:
{
"instance_id": "i-1234567890abcdef",
"message": "aSampleMessage"
}
In this way, the developer who writes his own code and has to execute his commands on the virtual machine can indicate both the machine and the execution parameters.
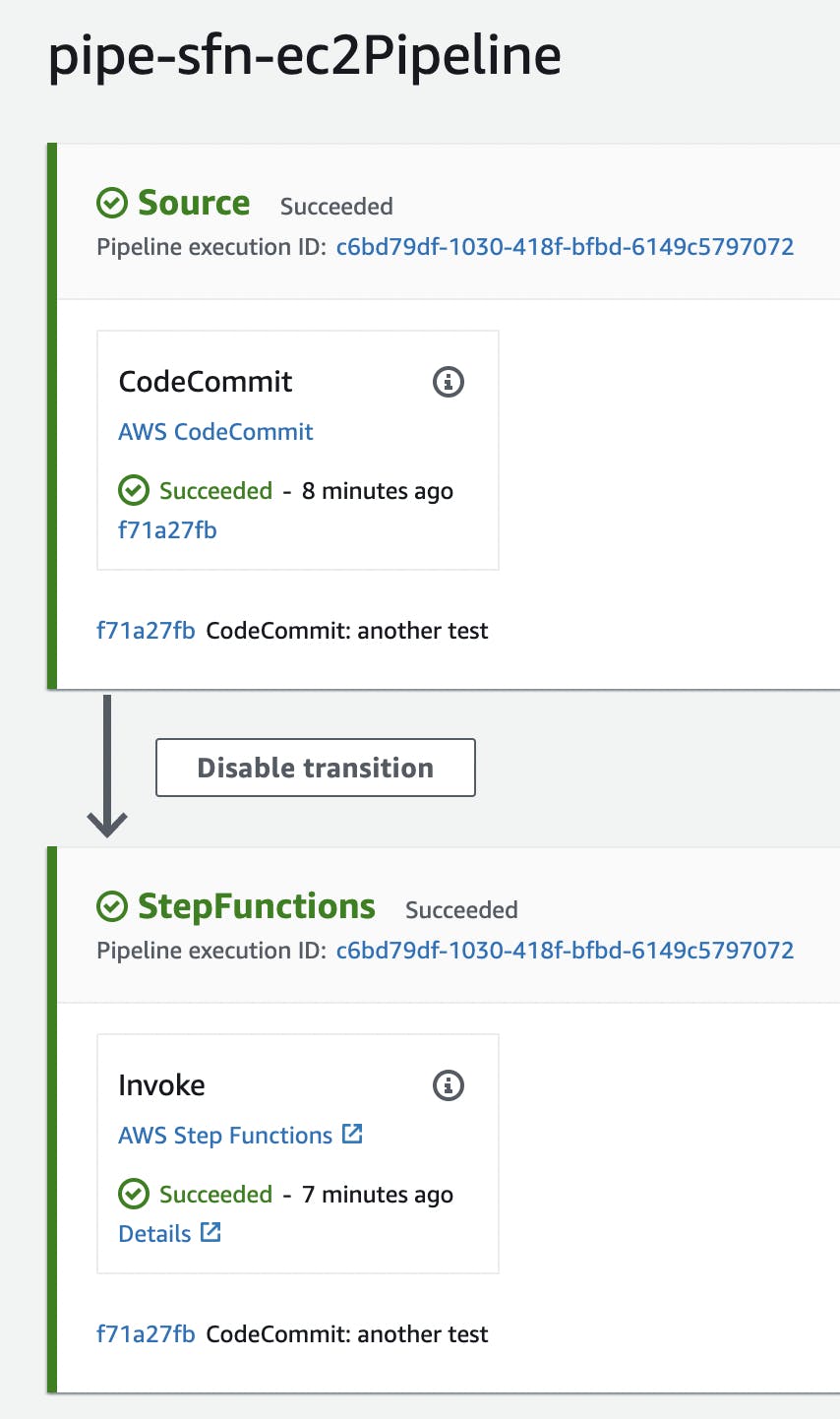
That's all! Once pushed, the pipeline starts automatically, downloads the code from the repository and launches the StepFunction:
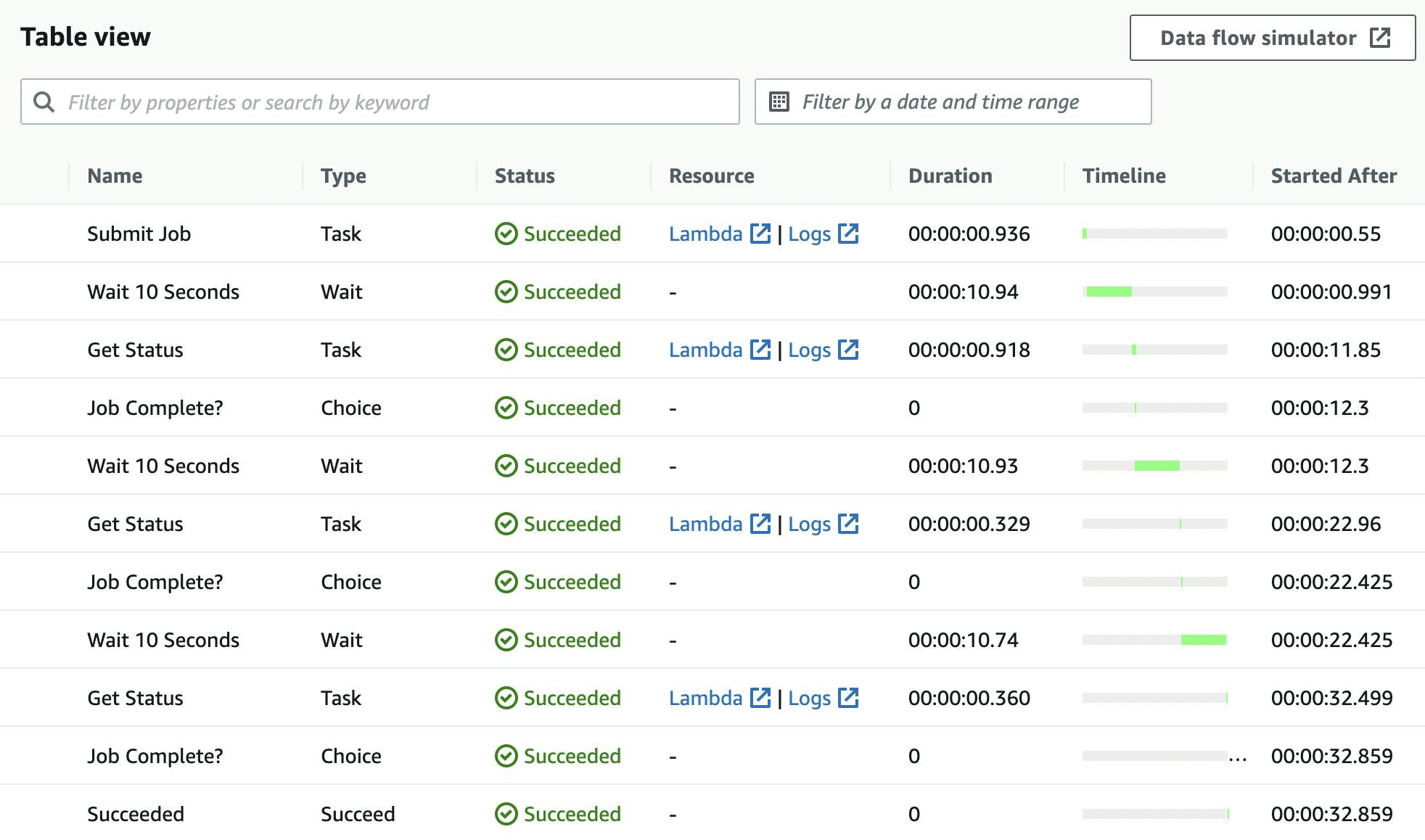
It is possible to consult the flow of the StepFunction execution:
You can also consult the execution of the SSM Document:
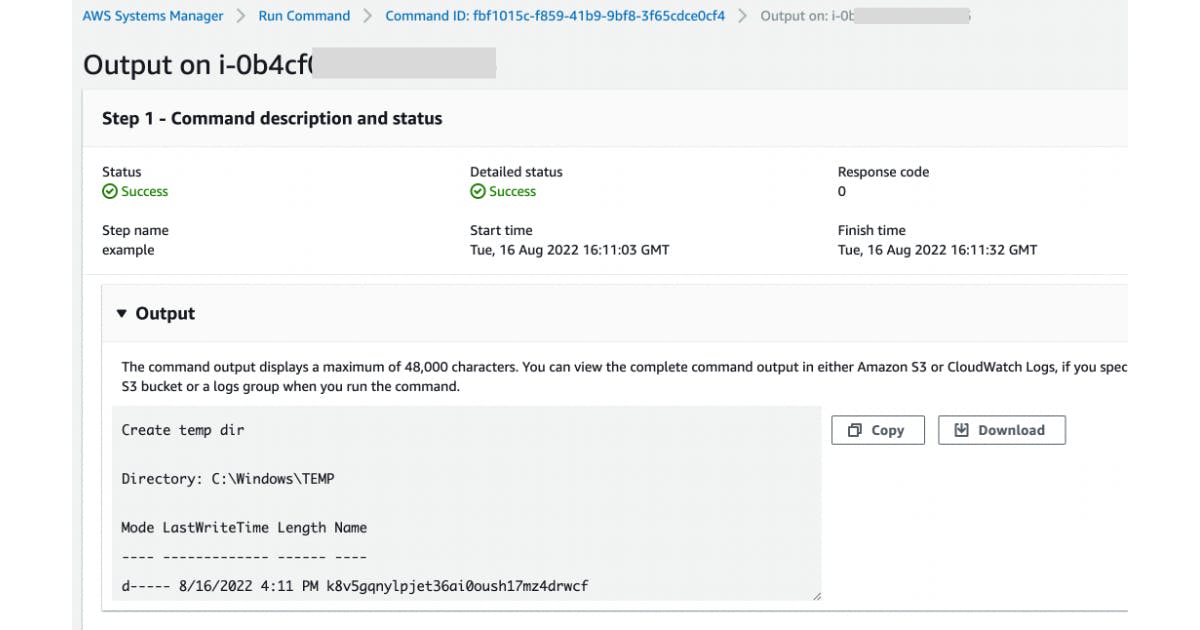
Considerations
Having constraints, imposed by organizational choices or by some kinds of software, is a very common situation, especially in large companies: this should not discourage the introduction of modern methodologies and technologies, because these technologies allow solutions for (almost) any integration.
The introduction of a StepFunction into the pipeline, which may seem like an overengineering in cases where commands take a few seconds to execute on a virtual machine, is actually indispensable when this execution takes a relatively long time.
Using AWS CDK dramatically shortens code writing time, as long as you are familiar with one of the supported programming languages.